« back published by Martin Joo on February 27, 2025
How MySQL indexes work?
In the last 13 years, I've used many programming languages, frameworks, tools, etc. One thing became clear: relational databases outlive every tech stack.
Let's understand them!
Building a database engine
Even better. What about building a database engine?
In fact, I've already done that. And wrote a book called Building a database engine.
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:

Data pages
Data pages and indexes are quite connected.
Earlier, I published an article that explains how database indexing works in theory. This is a very detailed article and shows you everything you need to know.
In this one, we're going to build a basic index. Please read the other one, if you're not sure how indexes work.
Here's an executive summary.
An index is a B+ tree:
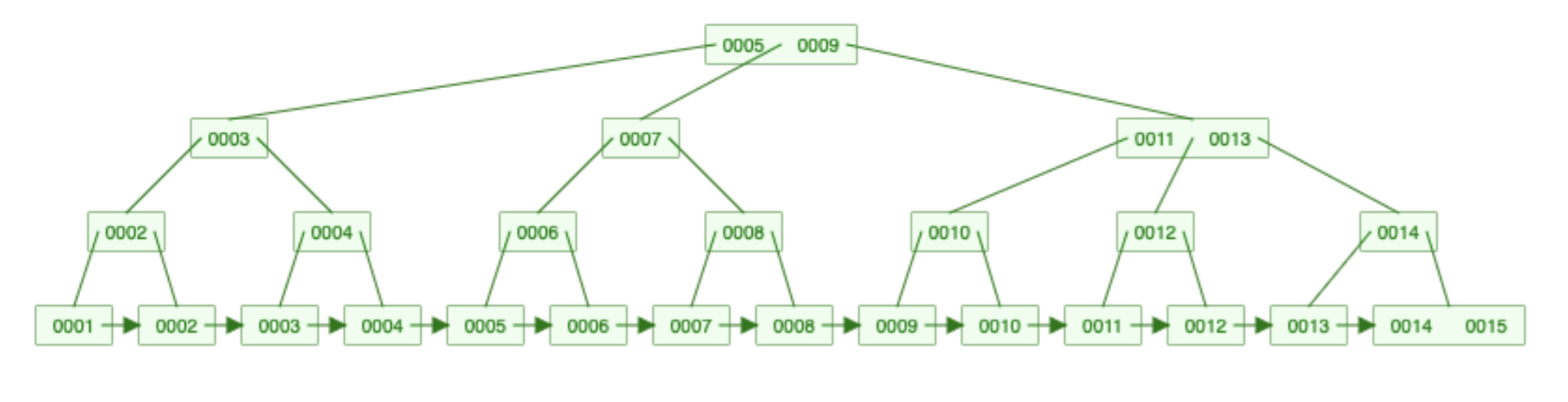
There are leaf nodes at the bottom and routing nodes in the middle. Leaf nodes form a linked list and they contain the actual data. If you add an index on username leaf nodes contain the usernames.
In a large enough tree, 99% of the nodes are at the bottom and only 1% of them are routing nodes. Because of that, a smart trick can be used: only routing nodes are loaded into memory. Imagine a 1TB table with a 100GB index. If every node would have been loaded you would need 128GB RAM in your server. But this way, the index will work with 16GB.
Leaf nodes don't store one record. They store thousands of them organized into data pages. Usually 4KB or 8KB. So each node contains 8KB worth of records.
There's a difference between clustered indexes (primary key created by the engine) and secondary indexes (our own indexes). A clustered index stores each column on the index. A secondary index stores only the ones you configured and the primary key value. If your query (that uses a secondary index) needs an additional column it can retrieve it from the clustered index.
In order to have nodes that store data pages, the table file also needs to be organized into pages:
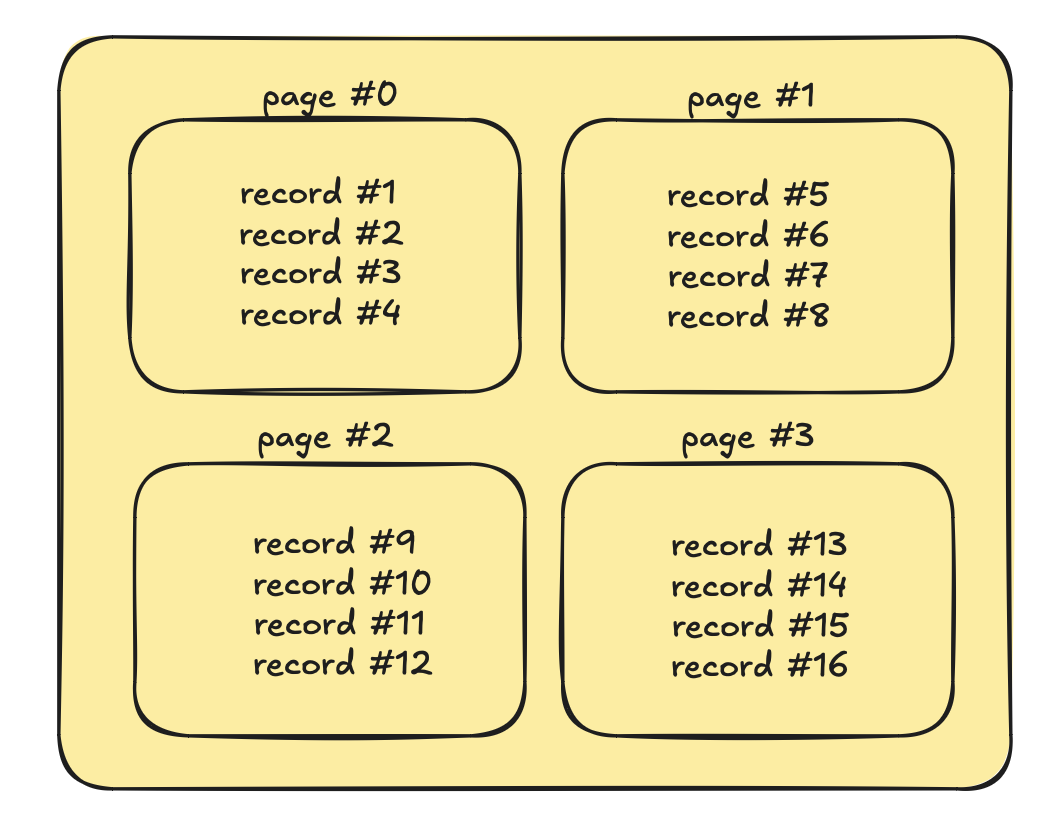
This represents a table with 4 pages and 16 records. Every command like insert, update, delete, or select needs to work with these pages. For example, insert needs to check if the new row would fit into page #3 and store it there or create a new page. Each page has a fixed size. A page can contain less data but no more than that.
Less is allowed. Consider this scenario:
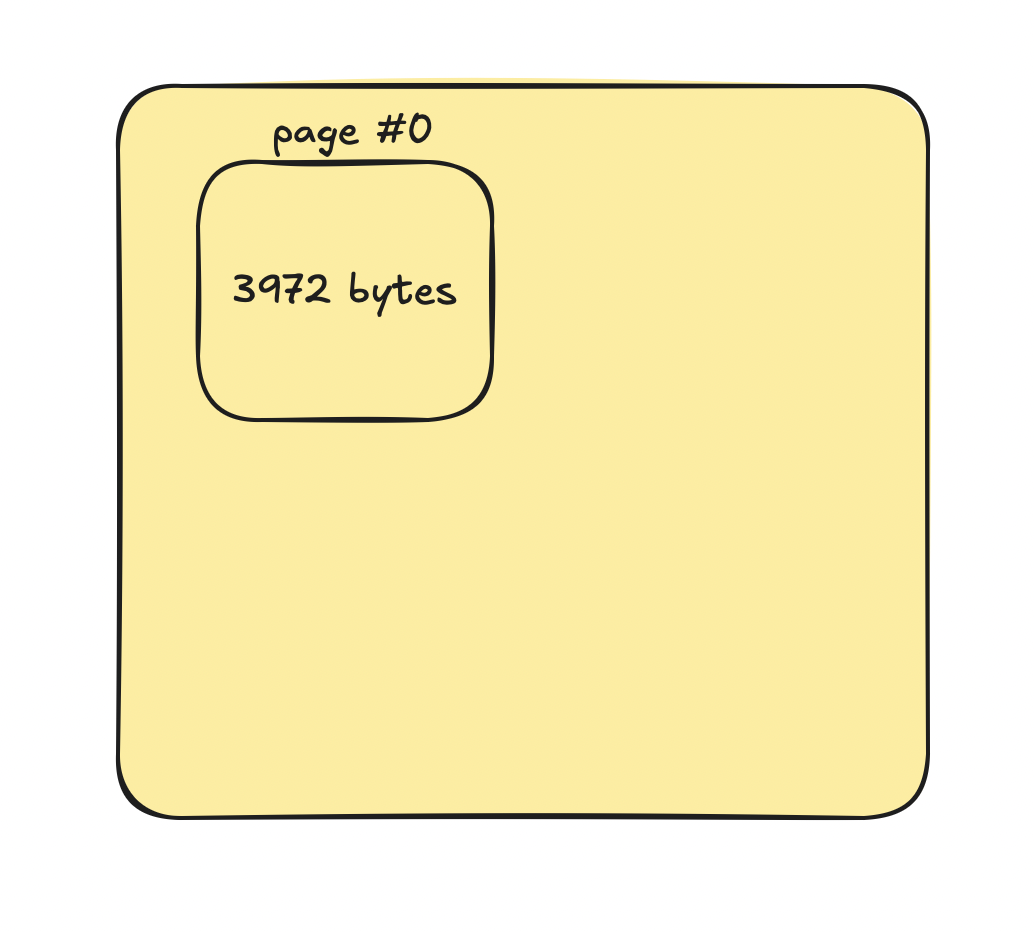
Let's say the page size is 4KB and we want to store another 572 bytes. It won't fit into page #0 so the engine creates a new one:
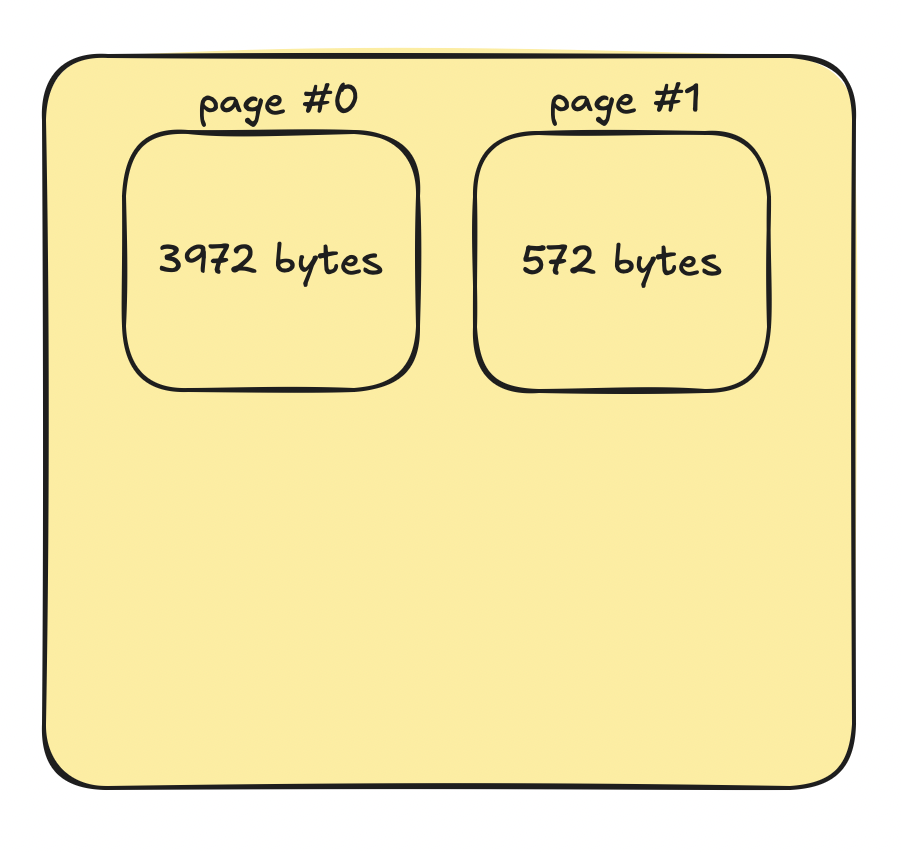
This page-based structure has lots of advantages.
More efficient I/O. Your SSD or HDD cannot read 32 bytes of data. It can only read an entire page. Which is 4KB, 8KB, 16KB, etc depending on your system. This fact is taken into account in your operating system and your programing language as well. For example, if you read 32 bytes from a file, the OS will read 4KB. It caches the data, and your language (such as Go) might implement buffered I/O on top that. Meaning if you read another 32 bytes from the same file you won't use the SSD again.
Also, reading 4KB of contiguous data (a page) is faster than fetching 40 100-byte records one by one.
More efficient indexes. As stated earlier, pages will be stored in indexes. Storing individual recrods are not efficient enough. If you have a 500MB table with 1,000,000 rows, the index would have 1,000,000 nodes. That is a huge data structure to hold in memory. Lots of metadata associated with each record, loops that run for 1M times, etc. For example, if the metadata is only 2 64bit integers (pointers), it would be 16,000,000 bytes. It is ~16MB. Only for storing two additional pointers. The same 500MB of data can be divided into 125,000 4KB pages or 62,500 8KB pages. Storing 2 pointers for 62.5k nodes takes ~1MB. The difference is 16x.
Also, since the number of nodes decreases significanlty scanning a table becomes faster. Tree-based data structures can be traversed in O(log N) time complexity. Traversing 62,500 nodes requires only 16 steps. This means, it cannot take more than 16 I/O operations to find one record in 1,000,000 using a B+ tree index with 8KB pages. Compare this to a full table scan!
Better caching. DB engines use caches to speed up our queries. If the OS reads 4KB of data even when we only need a 120-byte record, we should take advantage of that. We can load the entire page and put it into an LRU cache. LRU means least recently used and it maintains a cache with the N most used items. Basically, we can store the 10 most popular pages in memory. Serving these records requires 0 I/O operations.
B-Tree indexes
In this example, I'm going to use a B-Tree instead of a B+ Tree. The reason is simple: I wanted to use a package instead of writing it from scratch. I couldn't find a reliable B+ tree package for Golang. Sure, there are some packages but they all seem like abandoned hobby projects of solo developers. Some of them have weird behavior, like hard-coded fmt.Print calls, some of them only supports storing byte arrays, etc.
On the other hand, there's an amazing B-Tree package written by Google. It is 10 years old, still maintained, reliable, and well-tested. The package has zero dependencies and it is used in 50k repositories and 30k packages. Projects like Docker, Kubernetes, Minikube use this btree. 2D graphic libraries such as skia depend on this package. It's reliable
From our perspective, there's not a big difference in using a B+ Tree vs B-Tree.
Since the entire tree will be loaded into memory, we cannot store data pages in the nodes. It would be very memory consuming. A 1GB table would require 1GB of RAM. 100 of those would require 100GB RAM. If the database has a huge multi TB table we're out of luck.
Instead of storing the actual data in the tree, we can use pointers. Each node stores an ID and a position that points to a page:
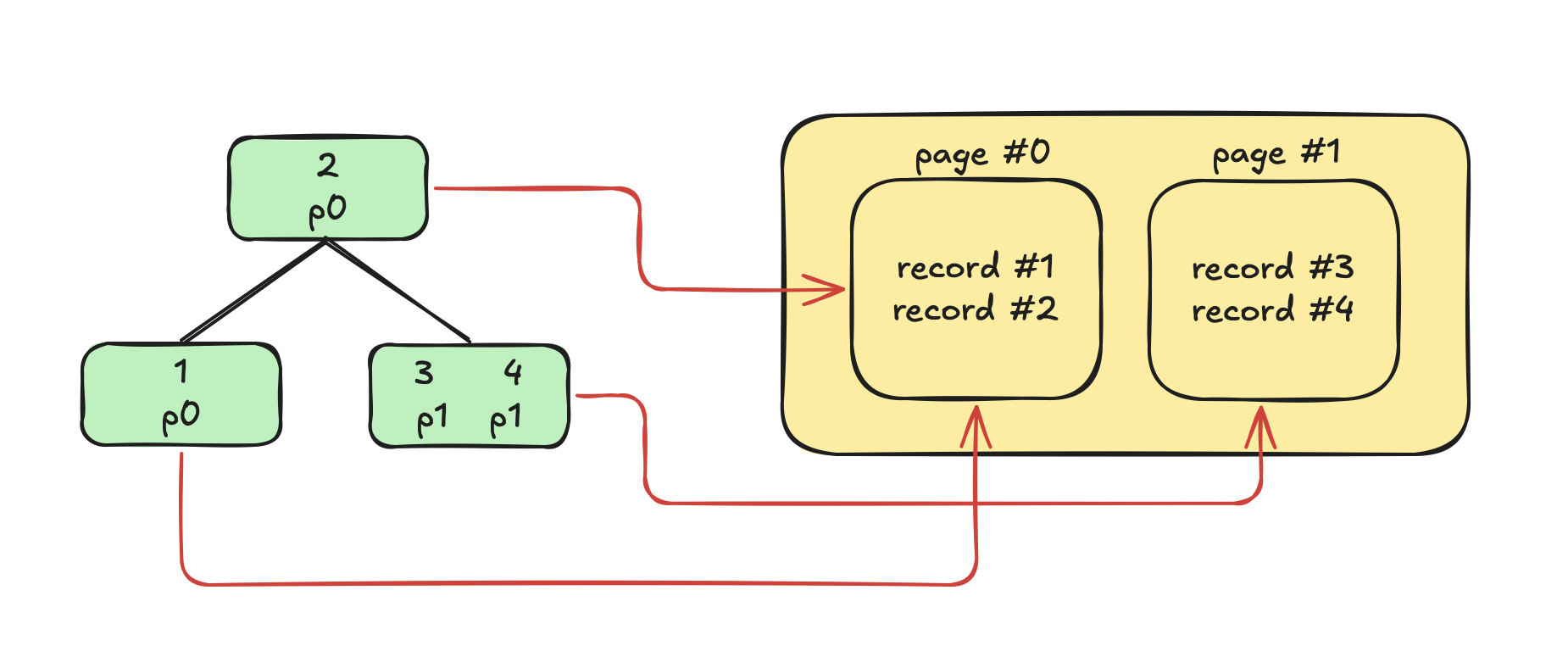
On the left you can see the tree where each node stores an ID and a pointer to a page. On the right, there's the table with two pages and four records. Red arrows represent the connection between nodes and records. p0 means page #0 and so on.
Just a quick reminder: B-Trees and B+ Trees are n-ary keys, meaning a node can have multiple values like the right child node in this example.
In the real implementation, nodes will have values such as (2, 768) which means record with the ID of 2 can be found in the page that starts at the 768th byte in the file.
So this is a more realistic representation:
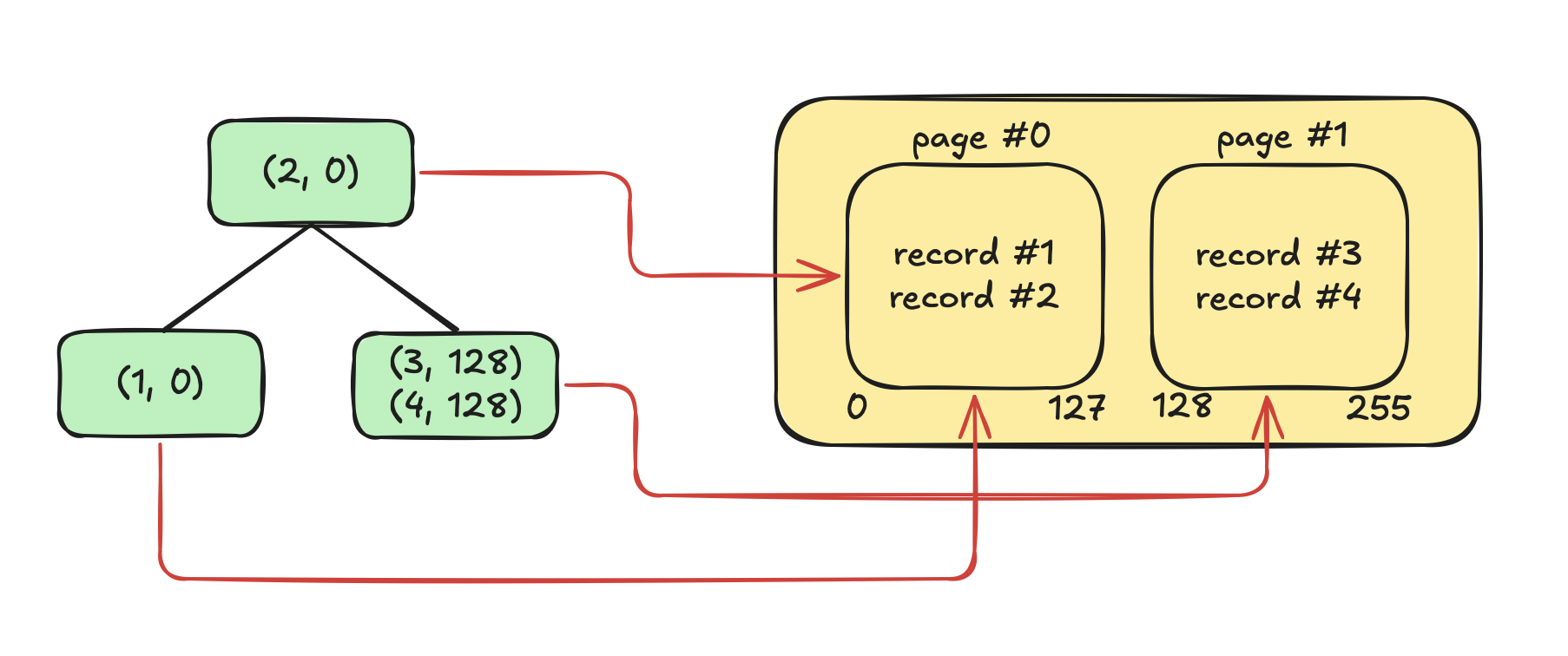
Page #0 starts at 0, page #1 starts at 128 so the tree has the following pairs:
(1, 0): ID 1 can be found in the page starting at byte 0, which is page #0(2, 0): ID 2 can be found in the page starting at byte 0, which is page #0(3, 128): ID 1 can be found in the page starting at byte 128, which is page #1(4, 128): ID 1 can be found in the page starting at byte 128, which is page #1
This is how our index will work. And this makes it possible to get any page from the file in just a few steps. To be more precise, O(log N) steps.
Implementation details
Let's say a table has 1,000,000 and we run a query like this:
select *
from users
where id = 10347;
This is how the engine will serve this query:
- The page in which user
10347is located can be found in just 20 steps using the B-Tree (log 1,000,000 = 19.9) - The file is seeked to the page's starting position
- The whole page is read into memory executing one I/O operation
- The record is located with a simple for loop running on an in-memory array
This an extremely effective process compared to a full table scan.
Of course, we're building a simplified engine, so we won't handle these situations:
- What if a record couldn't fit into one page?
- What if the query involves reading multiple pages? Such as
where id > 100 - Range queries
where id in (1,2,3,4,5) - Multiple where expressions
where in (...) and job = "..." - Secondary indexes
We only implement a clustered index for the primary key. To further simplify the code, columns don't have a primary key options so we require every table to have a column called id. Adding a primary key option is not a hard task, but it'll make everything more "meta" and harder to understand.
Adding an index
This is the Index type:
package index
import "github.com/google/btree"
type Index struct {
btree *btree.BTreeG[Item]
file *os.File
}
Indexes will be persisted as well. They are stored in a separate file to simplify our lives. The filename will be users_idx.bin.
btree comes from the Google package and it exports a type called BTreeG. G stands for generic. We can store custom objects on the tree.
In this case, nodes store Item objects:
type Item struct {
id int64
PagePos int64
}
An Item like this:
Item{
id: 10347,
PagePos: 7296,
}
Tells us that the user with ID 10347 is located in the page that starts at the 7296th byte in the table file.
Google's btree comes with a simple interface:
// Add "10" to the tree, or replace it if already exists
btree.ReplaceOrInsert(10)
// Remove "10" from the tree
btree.Delete(10)
// Find "10"
item, ok := i.btree.Get(10)
if !ok {
fmt.Println("10 not found in the tree")
}
We're going to use these methods by adding wrapper functions to the Index type. Function in Table will only interact with the Index type.
Each table contains an instance of Index so let's write a constructor:
func NewIndex(f *os.File) *Index {
bt := btree.NewG[Item](2, func(a, b Item) bool {
return a.id < b.id
})
return &Index{
btree: bt,
file: f,
}
}
btree.NewG takes two arguments:
-
2is thedegree. It determines how many items a node contains and how many children does it have. 2 means a node can hold 1,2, or 3 items, and it can have 2-4 children. -
The second argument is the
LessFunc. It determines how objects are ordered. In this case, it's based on the ID.
Each table has its own index so the type has a new field:
type Table struct {
Name string
file *os.File
columnNames []string
columns Columns
reader *platformio.Reader
recordParser *parser.RecordParser
columnDefReader *columnio.ColumnDefinitionReader
wal *wal.WAL
index *index.Index
}
When creating/reading tables, Database creates/loads the index and passes it to Table.
Building a database engine
This whole article comes from my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:
Insert
If you're familiar with DB indexing you probably know that an index makes inserts slower. It's because, after inserting a new record, it is also added to the B-Tree and it needs to be re-balanced.
In our case, the following things need to happen when inserting a new record:
- Add the new ID to the B-Tree
- Encode the tree into TLV
- Write it to disk
In Table.Insert we need to add the new entry:
func (t *Table) Insert(record map[string]interface{}) (int, error) {
// ...
page, err := t.insertIntoPage(buf)
if err != nil {
return 0, fmt.Errorf("Table.Insert: %w", err)
}
if err = t.index.AddAndPersist(record["id"].(int64), page.StartPos); err != nil {
return 0, fmt.Errorf("Table.Insert: %w", err)
}
return 1, nil
}
After the record is inserted into a page, we simply call AddAndPersist on Index.
This function encapsulates the logic of:
- Adding a new item to the tree
- Marshaling it
- Persisting it to disk
func (i *Index) AddAndPersist(id, pagePos int64) error {
i.btree.ReplaceOrInsert(*NewItem(id, pagePos))
return i.persist()
}
Since this is an insert, the Item created by NewItem will always be new, so ReplaceOrInsert inserts it into the tree and re-balances it.
persist will do the rest:
func (i *Index) persist() error {
if err := i.file.Truncate(0); err != nil {
return fmt.Errorf("index.persist: file.Truncate: %w", err)
}
if _, err := i.file.Seek(0, io.SeekStart); err != nil {
return fmt.Errorf("index.persist: file.Seek: %w", err)
}
b, err := i.MarshalBinary()
if err != nil {
return fmt.Errorf("index.persist: marshalBinary: %w", err)
}
n, err := i.file.Write(b)
if err != nil {
return fmt.Errorf("index.persist: file.Write: %w", err)
}
if n != len(b) {
return NewIncompleteWriteError(len(b), n)
}
return nil
}
The index file works a bit different than the table file. We always want to replace its content with new content.
Calling these functions:
- Truncate
- Seek
- Write
Is a way to overwrite an existing file.
That's the entire logic needs to happen when inserting a new row.
We can use the Ascend function to get all items from the tree:
func (i *Index) GetAll() []Item {
out := make([]Item, 0)
i.btree.Ascend(func(a Item) bool {
out = append(out, a)
return true
})
return out
}
It iterates through the tree in an ascending order.
The result is something like this:
[{1 430} {2 430} {3 559}]
In this example (inserting 3 records into 128-bit pages), there are two records in page 0 at 430 and another one in page 1 at 559.
Select
There are at least two ways to use the index in select:
- Seeking the file to the desired page and read it record-by-record
- Seeking the file to the desired page and read the entire 4KB block. Then process it record-by-record, in-memory.
The first one is super easy. We only need an additional Seek and everything works the same.
The second might be a more efficient solution because it involves less system calls (only one read operation).
Let's implement both of those versions.
Reading individual records
I wanted to start with this, because it's surprisingly simple:
func (t *Table) Select(
whereStmt map[string]interface{}
) ([]map[string]interface{}, error) {
if err := t.ensureFilePointer(); err != nil {
return nil, fmt.Errorf("Table.Select: %w", err)
}
results := make([]map[string]interface{}, 0)
fields := make([]string, 0)
for k, _ := range whereStmt {
fields = append(fields, k)
}
// use the index to seek the file to the right page
if slices.Contains(fields, "id") {
item, err := t.index.Get(whereStmt["id"].(int64))
if err == nil {
if _, err = t.file.Seek(item.PagePos, io.SeekStart); err != nil {
return nil, fmt.Errorf("Table.Select: file.Seek: %w", err)
}
}
}
// ...
}
As you can see, it only uses the index if query contains an expression like this: where id = 6
The logic is simple:
- Find the given ID in the tree
- Seek to
item.PagePos
After file.Seek the file pointer points to the right page:
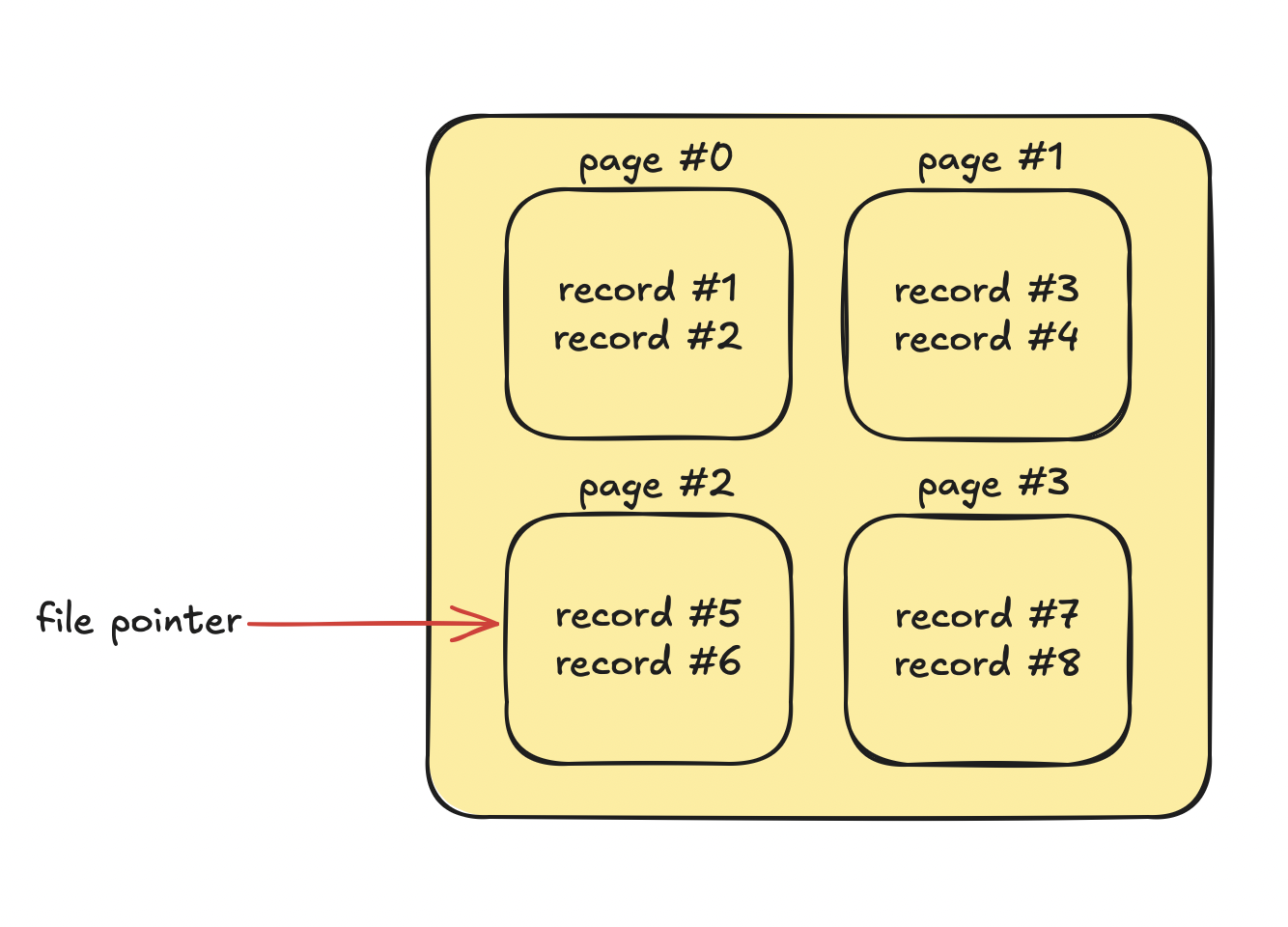
And RecordParser can start reading records. It doesn't matter if the file points to the beginning of the file, or the 3rd page. It's all the same:
func (t *Table) Select(
whereStmt map[string]interface{}
) ([]map[string]interface{}, error) {
// ...
// use the index to seek the file to the right page
if slices.Contains(fields, "id") {
item, err := t.index.Get(whereStmt["id"].(int64))
if err == nil {
if _, err = t.file.Seek(item.PagePos, io.SeekStart); err != nil {
return nil, fmt.Errorf("Table.Select: file.Seek: %w", err)
}
}
}
for {
err := t.recordParser.Parse()
if err == io.EOF {
return results, nil
}
// ...
}
}
Optimizations
All database engines come with a query optimizer. It analyzes your query and tries to come up with the most cost effective way to get the data. They do things such as:
- Estimating the cost of various operations. It uses metadata such as table size, index cardinality, data distribution, etc to estimate how expensive a given operation (such as using an index) would be.
- Based on these costs it comes up with an execution plan that includes:
- Access method (full table scan, index, etc)
- Decide the best join order to minimize intermediate result sets avoiding using lots of memory and CPU
- Index usage. There can be multiple indexes so the optimizer decides which is one is the best for the given. In somce cases, it can decide to skip an index entirely, or merging them together.
- Sorting/grouping. Chooses between filesort or index-based sorting.
- Converting subqueries into joins or temparory tables if possible.
- And lots of other things
The point is that it creates an execution plan for your specific query.
For example, it might decide to do completely different things given these two queries:
select * from users where id = 100;
select * from users where id > 1000 and id < 100000;
You probably already guessed that the first one will use the const access type because only one record is selected. These queries are quite common, and they can be very fast and cost effective with the right optimization.
Our current select has a major flaw. Even if the query results in only one record, and we seek the file by reading the index, the for loop will read the entire file from the starting point.
// This seeks the file to the starting point
if slices.Contains(fields, "id") {
item, err := t.index.Get(whereStmt["id"].(int64))
if err == nil {
if _, err = t.file.Seek(item.PagePos, io.SeekStart); err != nil {
return nil, fmt.Errorf("Table.Select: file.Seek: %w", err)
}
}
}
// This reads the one record we need, and then goes until EOF
for {
err := t.recordParser.Parse()
if err == io.EOF {
return results, nil
}
// ...
}
When the file is seeked to the right page, the first fews iterations of the loop will read the disered record. But after that, it will go on until it reaches EOF. Which is completely unnecessary. A waste of resources.
After finding the desired record the function should return. Like a const type query does in a production DB.
This represents a page in which the second record is the desired one:
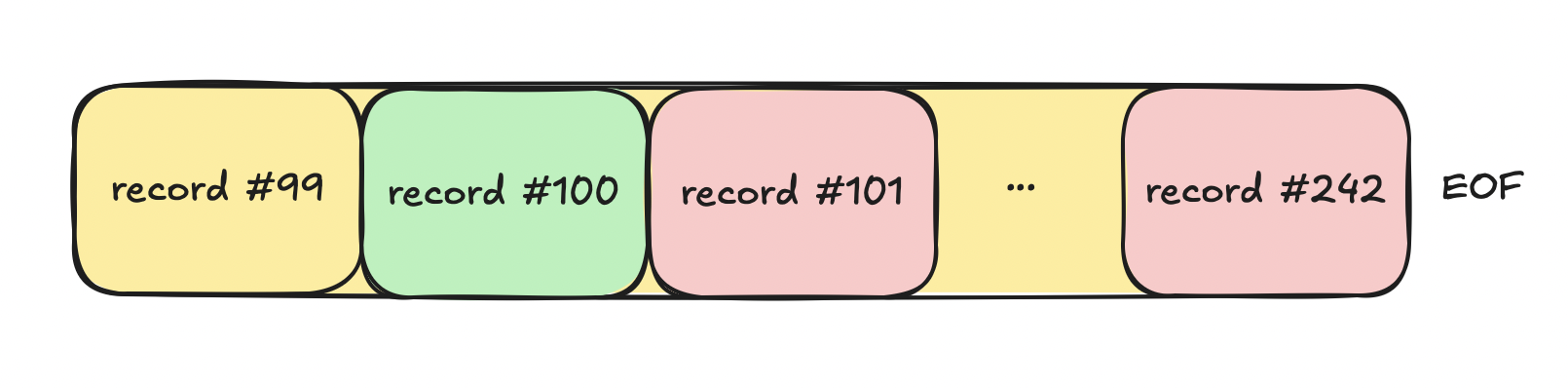
Everything after record #100 is a waste of time when the query is:
select * from users where id = 100;
We won't build a query optimizer, but we can simulate a const access type. Our DB only supports the equal operand in where statements. When the ID is present in where we already know it should be a const query with a single result:
func (t *Table) Select(
whereStmt map[string]interface{}
) ([]map[string]interface{}, error) {
// ...
singleResult := false
if slices.Contains(fields, "id") {
singleResult = true
// ...
}
}
When the where expression contains the id field we set singleResult to true.
The loop that invokes RecordParser can be stopped using the flag. Showing only the important parts:
func (t *Table) Select(
whereStmt map[string]interface{}
) ([]map[string]interface{}, error) {
// ...
for {
err := t.recordParser.Parse()
if err == io.EOF {
return results, nil
}
if !t.evaluateWhereStmt(whereStmt, rawRecord.Record) {
continue
}
if singleResult {
return results, nil
}
}
}
At the end of the loop, it returns early if singleResult is true and it already parsed one record.
Building a database engine
This whole article comes from my new book - Building a database engine. It contains much more info about indexes and data pages.
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out: