« back published by Martin Joo on March 5, 2025
Designing a database storage engine
DBMS (database management system) vs storage engine
There are two important concepts in databases:
- DBMS
- Storage engine
InnoDB is a storage engine. Its main responsibilities include:
- Data storage
- Data retrievel
- Indexing
- Caching
- Concurrency control
- ACID
MySQL is a DBMS. It's responsible for things like:
- User interface (CLI)
- Server and client component
- Query processing
- Query optimiziation and execution
- Backup and recovery
- Transaction management
- Security and access management
- Buffer management (optimizes data transfer between disk storage and memory)
You can think about a storage engine as a library, a package. No servers. No clients. Just a library with functions.
Functions such as:
insert()update()delete()select()
A DBMS takes a storage engine and makes it an executable server. It also provides a client so we can interact with the data using CLI or GUI tools.
SQL or an SQL parser is not part of a storage engine. It is provided by the DBMS. When you run a query, something like this happens:
- MySQL parses your query
- It optimizes it using the optimizer
- It chooses the optimal execution plan
- Then it executes functions provided by InnoDB
And then there's SQLite. It is both a DBMS and a storage engine. Without a server or a client.
Designing a database storage engine is cool.
You know what's even cooler?
Building a database engine
This whole article is based on my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:

Data storage
A naive approach
The most important part of a storage engine is... Storage.
We often think about data as an Excel sheet, a CSV file, or a JSON object. These are good formats for human-friendly display.
The moment you send that HTTP request, however, your fancy JSON becomes a sequence of bytes.
The same goes for databases, too.
But first, let's see why something like a simple separator-based CSV format would not work.
Take this example:
id;name\n
1;user1\n
2;user2\n
3;user3\n
How would you select row #3 from this table? Let's say we already processed the header row and the file pointer points to 1.
My algorithm would look like this:
- Read the current byte (ID)
- Is it
3? No. It is1 - Read the next byte
- Is it
\n? No. It is; - Read the next byte
- Is it
\n? No. It isu - Read the next byte
- Is it
\n? No. It iss - Read the next byte
- Is it
\n? No. It ise - Read the next byte
- Is it
\n? No. It isr - Read the next byte
- Is it
\n? No. It is1 - Read the next byte
- Is it
\n? Yes - At this point we reached the end of row #1 and a new ID comes next
- Read the next byte (ID)
- Is it
3? No. It is2 - ...
I thnk you get the point.
The engine needs to read the whole table byte by byte.
There's no other way to know where the current row ends and the next one starts. It needs to process every byte and find the \n characters.
If your table is 500MB (which is not that large), this loop can run up to 500,000,000 iterations.
Fixed-size columns
The main problem is that the engine doesn't know the length of the data. Let's fix it.
Delimiters can be removed by having fixed-size rows. name if fixed to 16-bytes:
1johndoe.........
2user2...........
3jane_doe........
. characters represent empty bytes.
This is just a toy example, so we treat the IDs as if they were characters. For now, they always take 1 byte and they are characters.
If the fix size of the name column is 16 bytes then every row is exactly 17 bytes long. This is a big improvement, because now we can write a much better algorithm:
- Read the current byte (ID)
- Is it
3? No. It is1 - Skip 16 bytes
- Read the next byte (ID)
- Is it
3? No. It is2 - Skip 16 bytes
- Read the next byte (ID)
- Is it
3? Yes
Can you see the difference?
Instead of reading the table byte by byte now we can process it row by row.
This is a huge improvement.
Given a 640MB table with 4M records:
- Byte-by-byte algorithm: 640,000,000 possible iterations
- Row-by-row algorithm: 4,000,000 possible iterations
The difference is 160x
But the fixed-size version has a big disadvantage, too: wasting space.
A mediumtext column is 16,777,215 bytes in MySQL. It's 16MB.
Imagine allocating 16MB of space for storing 319 characters, for example.
If you have 1,000,000 records it would take 16.78TB just to store the mediumtext column.
Variable size columns
Imagine the following:
17johndoe
25user2
38jane_doe
17 in the first row is not really 17 but 1 and 7:
1is the ID7is the length of the name that follows
Now the algorithm works in the same way, but we don't waste space:
- Read the current byte (ID)
- Is it
3? No. It is1 - Skip 7 bytes
- Read the next byte (ID)
- Is it
3? No. It is2 - Skip 5 bytes
- Read the next byte (ID)
- Is it
3? Yes
It's a win-win. Fast lookup that doesn't waste space.
TLV (Type-Length-Value)
Most databases, network protocols, proto buffers, and other lower-level components use TLV.
You can encode anything by storing its:
- Type
- Length
- Value
What is a type?
It's an arbitrary flag.
Say we want to encode integers and strings in a language, OS, and platform agnostic way.
First, we need to associate different data types with arbitrary flags, for example:
| Arbitrary flag | Type |
|---|---|
| 1 | integer |
| 2 | string |
That's it. A simple type-table.
Length and value are easy, too. We already used it in the previous example:
7johndoe
7 is the length and johndoe is the value.
To make it a valid TLV record:
27johndoe
It's a string (2) with a length of 7 and the value is johndoe.
Easy.
An int64 would look like this:
183894
1for integer8for 8 bytes3894for the actual value
This is the encoding format behind most database storage engines. There are more advanced variations that save space and encode the data in a more compact way, but this is the foundation for all of them.
Given the following table:
| ID | username | age | job |
|---|---|---|---|
| 1 | johndoe | 29 | software engineer |
| 2 | jane_doe | 24 | musician |
| 3 | user3 | 38 | designer |
And this type-table:
| Arbitrary flag | Type |
|---|---|
| 1 | int64 |
| 2 | string |
| 3 | byte |
The TLV representation would look like this:
1 0008 00000001
2 0007 johndoe
3 0001 29
2 0017 software engineer
1 0008 00000002
2 0008 jane_doe
3 0001 24
2 0008 musician
1 0008 00000003
2 0005 user3
3 0001 38
2 0008 designer
I represented lengths on 4 bytes and types on 1 byte.
Of course, all strings would be in UTF encoding. Numbers are usually expressed in little-endian. And the whole file would be in binary format. Without the extra whitespaces.
Data pages
Your SSD cannot read 1 byte of information. The smallest unit is one block. Which is 4KB, 8KB, or 16KB depending on your system.
It has historical reasons. The spinning thing on HDDs.
Operating systems evolved with this in mind. Even if you need 240 bytes, your OS might read 4KB and cache it. Subsequent system calls to the same file won't cause additional I/O operations.
Programming languages evolved the same way. They use buffered I/O to make this as seamless as possible.
Databases storage engines evolved the same way.
They organize tables into pages. These are 4KB, 8KB, or 16KB parts of your data in one chunk:
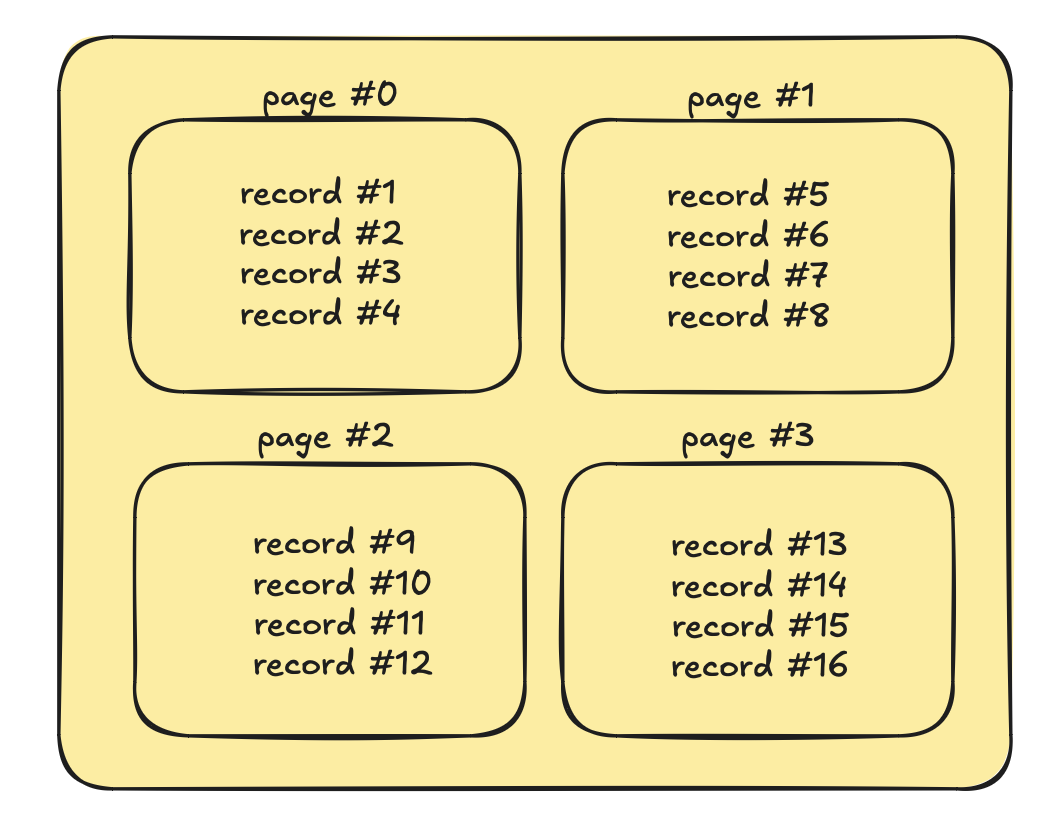
Records are variable sized. Pages have a fixed maximum size. Such as 4KB.
There are a number of problems database engines need to solve. Just to name a few:
What happens when a record doesn't fit into one page?
MySQL (InnoDB) uses an overflow page. The main page contains a pointer to one or more overflow pages where the rest of the record is stored. This works on the row level.
Postgres on the other hand, uses TOAST. By default, any value larger than about 2KB will be considered for TOASTing. When a value is TOASTed, it's moved to a separate TOAST table associated with the main table. In the main table, the large value is replaced with a TOAST pointer. It sounds similar to MySQL, but this works on the column level.
What happens with gaps in pages?
Let's say there are small gaps in pages. 200 bytes of empty space here, 57 bytes there.
Something like this:
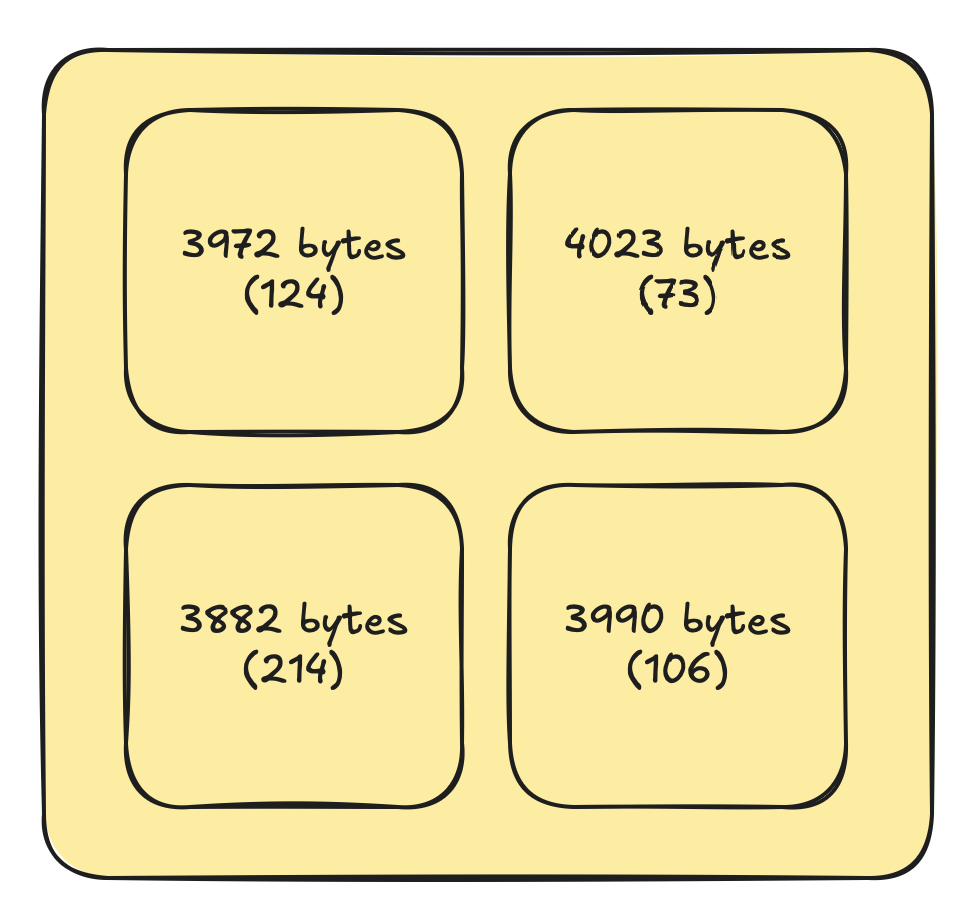
Numbers in parenthesis represents the empty space (the "gap") in pages.
If an "average" row in this table is 500 bytes these gaps are just wasted space.
MySQL (InnoDB) maintains a free space list within each page. Gaps are tracked in this list. When inserting new records, InnoDB tries to use these gaps if they're large enough. It can split records across pages if necessary.
Over time, these small gaps can lead to page fragmentation. OPTIMIZE TABLE can reorganize pages, potentially consolidating small gaps.
Postgres uses techniques like VACUUM, HOT (Heap-Only Tuple), and TOAST to fight fragmentation.
Simple example
Using one table file and TLV, we can add a new type for pages:
| Arbitrary flag | Type |
|---|---|
| 1 | int64 |
| 2 | string |
| 3 | byte |
| 255 | page |
Page is another value that can be encoded into a TLV record using the 255 type-flag:
255 53
1 8 00000001
2 7 johndoe
3 1 29
2 17 software engineer
255 is the type flag for a page and 53 is the length of it. Then it contains the bytes we've seen earlier. In this simple example, the value of a page is another TLV records.
A more realistic representation would be something like this:
255 58
100 53
1 8 00000001
2 7 johndoe
3 1 29
2 17 software engineer
All columns are organized under a 100 type flag. This represents an entire record. The value of a record is a number of TLV records (representing columns). The value of a page is a number of TLV records (representing rows).
This is a page with two columns:
255 112
100 53
1 8 00000001
2 7 johndoe
3 1 29
2 17 software engineer
100 54
1 8 00000002
2 8 jane_doe
3 1 25
2 17 software engineer
Building a database engine
This whole article is based on my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:
Indexing
I published a very detailed article on database indexing. It's 8,000 words. If you want to know more, please check it out.
B+ tree
In most databases (such as MySQL or Postgres), an index is a B+ tree:
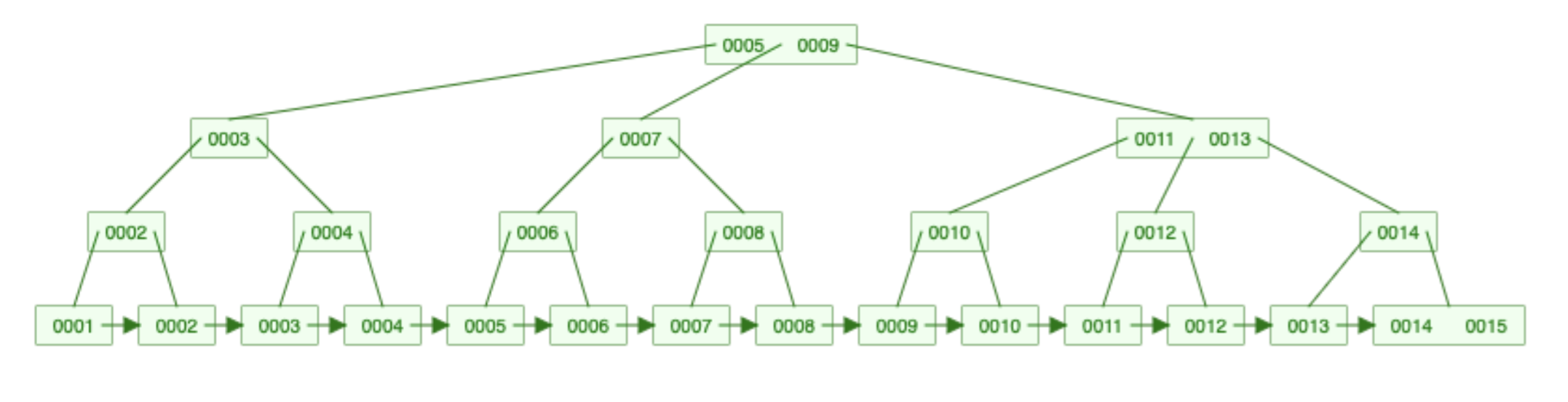
It stores your data in a sorted, hierarchical way. Those numbers represent IDs.
There are two kinds of nodes:
- Leaf nodes are at the bottom and they form a linked list.
- Routing nodes are at the top
A B+ tree is an N-ary key. Meaning each node contains multiple values. For example, the root node contains 5, and 9. The bottom right node contains 14, and 15.
In a real database engine, a node contains thousands of values.
To be more precise. Each node contains an entire page. If a page is 8KB and it contains 1,000 rows, then a B+ tree node contains 1,000 values.
This is only true for the leaf nodes!
Routing nodes only contain pointers to other nodes.
Only routing nodes are stored in the memory. Otherwise, we would run out of memory.
These nodes only account for 1% of the entire tree (they only contain integer pointers). So it's super lightweight.
In just O(log N) time they navigate the engine to the right leaf node.
From that point, reading a page is only 1 I/O operation. This returns potentially hundreds or thousands of records. This is very efficient for a range query and caching purposes.
This makes lookups very fast.
If the engine needs multiple pages, it's super efficient because of the linked list.
Serving this query:
select *
from users
where id in (1,2,3,4,5)
Looks like this:
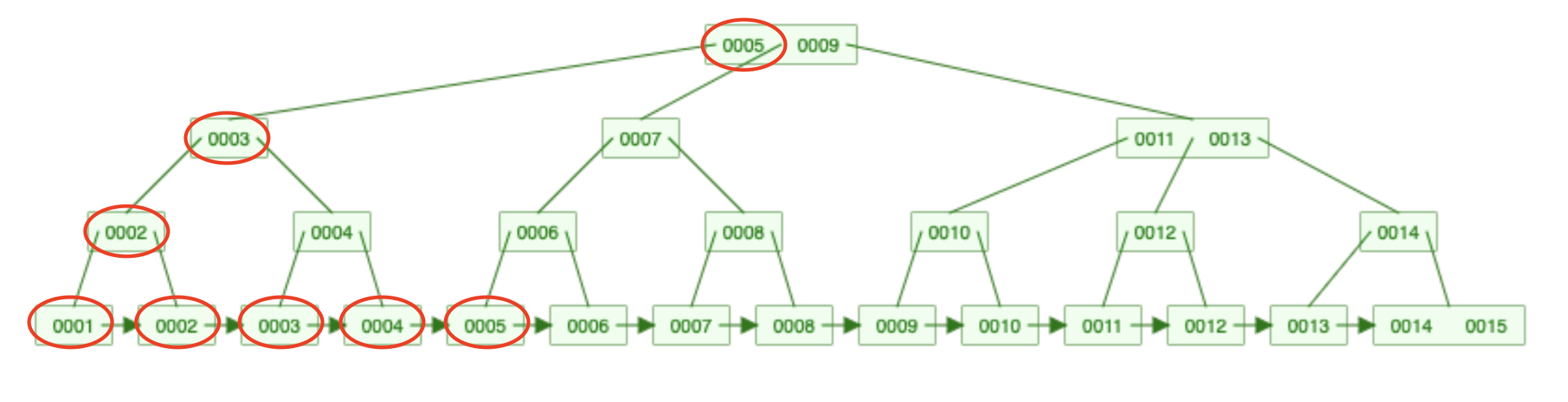
The process goes like this:
- 5 at the root
- 3
- 2
- Then (1,2,3,4,5) by traversing the linked list
And again, in a real engine these 5 users would be stored in one page instead of five.
If this was too fast for you, please check out this article on database indexing.
B-tree
Some database storage engines use B-Trees instead of B+ trees. Or at least did in the past (such as Mongo if I'm not mistaken).
This is a B-Tree:
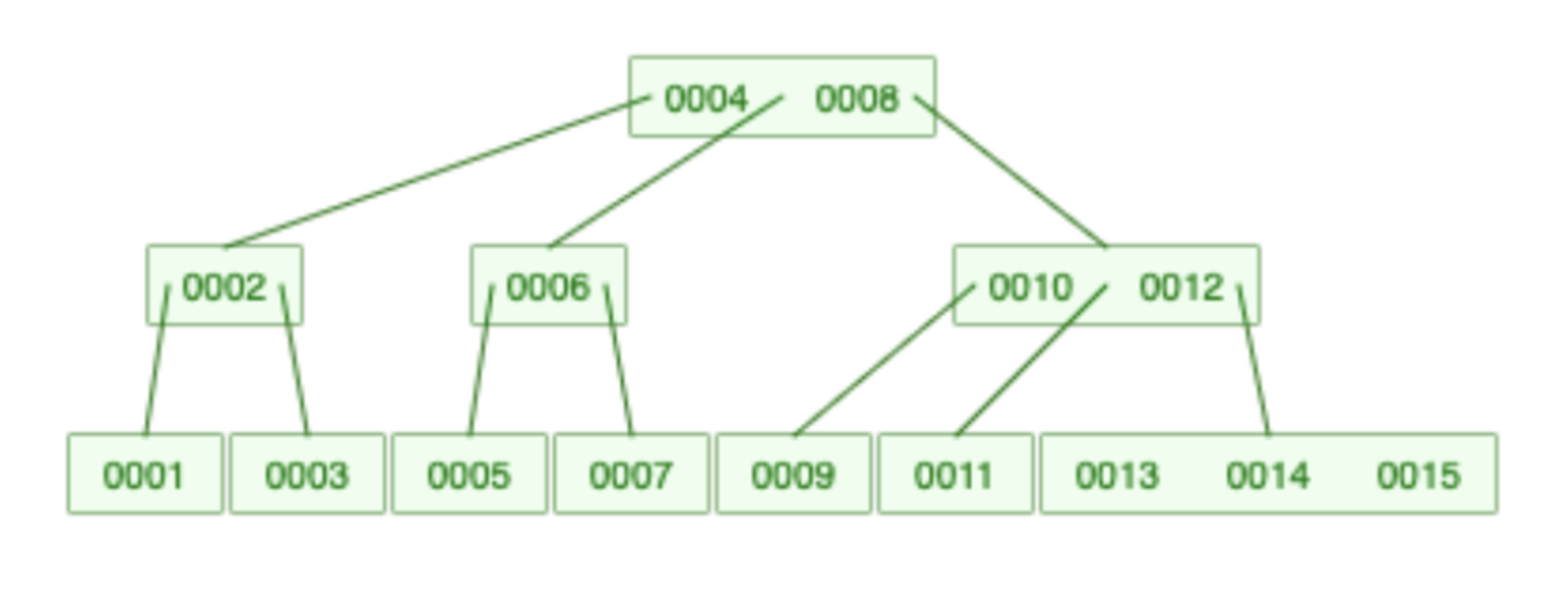
The difference is that there are no linked list, and each value is only presented once.
In a B+ Tree is easy to differentiate between routing and leaf nodes. Hence it's easy to load only the routing nodes into memory.
This is not the case with a B-Tree. I mean, technically it can be done, but it's quite complicated.
In other words, storing entire pages on the nodes is not a good idea. Because you'll run out of memory pretty fast.
When using a B-Tree it's smarter to store only pointer on the nodes. Pointers to pages.
Something like this:
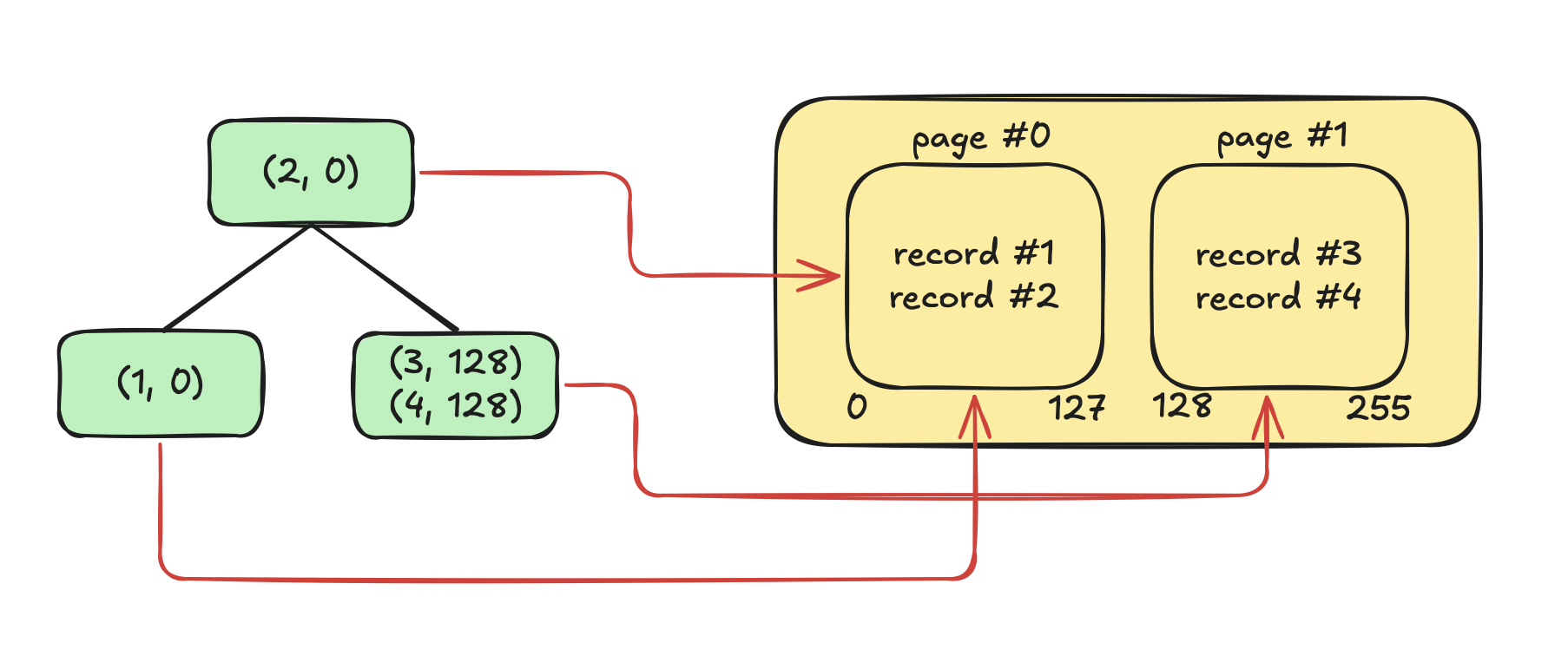
(2, 0)in the root node means that the row with ID #2 can be found in page #0 where 0 refers to the byte position of the page.(3, 128)means that the row with ID #3 can be found in page #128 where 128 refers to the byte position of the page.
This will also drasticaly speed up SELECTs since the position of a row can be found in just O(log N) time. And this time is spent in memory. After that, it's one I/O operation to read the page that contains the record.
WAL (Write-Ahead Log)
What happens if the server crashes while inserting a record into a table? What happens if you run 10 inserts but the 4th one fails?
The database is probably left in an inconsistent state. Or the table file is corrupted. Meaning, only part of the data was written successfully and we left the file in an invalid state.
Transactions help solve some of those problems. But a single insert can also fail mid operation.
One of the most important fault tolerance mechanisms is WAL or write-ahead log. This is how it works:
- When an operation is executed it is written to a write-only log. This is the WAL.
- Each log entry has attributes like:
- Unique ID
- Operation type (insert, delete, update)
- Data (the newly inserted row, for example)
- When the operation finishes the WAL is written to disk. But not to the table file. There's a separate file for the WAL itself.
- Once the data is safe in the log file it is updated in the table files.
Real database engines use WAL together with transactions. So the real flow looks like this:
- The transaction starts
- Each operation is written to an in-memory WAL
- The transaction finishes
- The in-memory WAL is writte to a log file
- Changes are recorded in the table files
This means that the WAL file contains the most updated state at any moment. If, for some reason, writing to the table file fails, the WAL still contains the lost data.
What happens if the server crashes while writing to the table file? At the next startup, data can be restored from the WAL file.
Let's model a simplified WAL with pseudo-code.
This is how the process works:
- Before writing to the table file, the engine will append the new record to the log file
- This new log entry has a unique ID
- It writes the data to the table file
- Then it "commits" the ID
The last step is very important and it has nothing to do with tranactions.
There are two branches the execution can take:
- The
insertis executed successfully - It fails
Successful insert
Let's imagine this scenario with pseudo-code:
insert(record) {
uniqueID = wal.append(record)
file.write(record)
wal.commit(uniqueID)
}
append writes the record and some metadata to the write-ahead log:
| unique ID | operation | data |
|---|---|---|
| wal-1 | insert | {"username": "user1", ...} |
| wal-2 | insert | {"username": "user2", ...} |
| wal-3 | insert | {"username": "user3", ...} |
Let's say user3 is the record we want to insert. It is now appended to the log.
Next, the function writes user3 into the table file.
As the last step, we need to "commit" the ID wal-3 because we know it is successfully written to the table file. So at the next startup wal-3 doesn't need to be restored. It is safe.
For now, you can imagine commit as a flag in the log file:
| unique ID | operation | data | committed |
|---|---|---|---|
| wal-1 | insert | {"username": "user1", ...} | true |
| wal-2 | insert | {"username": "user2", ...} | true |
| wal-3 | insert | {"username": "user3", ...} | true |
In other words "committed" means "is it written to the table file as well?"
When wal.append first appends the row, committed is false. And then wal.commit sets it to true.
Failure
Now let's see what happens when things don't work out as expected:
insert(record) {
uniqueID = wal.append(record)
err = file.write(record)
if err != nil {
return err
}
wal.commit(uniqueID)
}
The record is appended to the log with commited=false
| unique ID | operation | data | committed |
|---|---|---|---|
| wal-1 | insert | {"username": "user1", ...} | true |
| wal-2 | insert | {"username": "user2", ...} | true |
| wal-3 | insert | {"username": "user3", ...} | false |
Then file.write fails so the record is not written to disk and the log entry is not committed.
At the next startup, the engine checks uncommitted entries and tries to persist them into the table file:
startup() {
wal.restore()
}
// in the WAL package
restore() {
// returns wal-3
entries := getUncommittedEntries()
for e := range entries {
insert(e.data)
}
}
It reads uncommitted entries from the WAL file and inserts them into the table.
This is an oversimplified version of WAL. For example, partial write errors can still happen. Meaning, file.write writes some bytes and then fails. In this case, the table file is left in a bad state.
The next steps
These were the most crucial features of a database storage engine.
If you want to learn more, and see how these features are implemented, you should check out my new book.
Building a database engine
This whole article is based on the book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out: