« back published by Martin Joo on February 24, 2025
Understanding ACID
In the last 13 years, I've used many programming languages, frameworks, tools, etc. One thing became clear: relational databases outlive every tech stack.
Let's understand them!
Building a database engine
Even better. What about building a database engine?
In fact, I've already done that. And wrote a book called Building a database engine.
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:

I know this is “yet another ACID article” but if you don’t learn anything new after reading this, I’ll buy you a drink.
ACID It stands for:
- Atomicity
- Consistency
- Isolation
- Durability
Atomicity
Atomic refers to something that cannot be broken down into smaller parts. It’s a single unit of work, for example:
insert into users(username, age) values ("johndoe", 29);
This is a single unit of work. It either succeeds or fails. There’s no in-between.
That’s easy, of course, but what about this?
insert into orders(user_id, amount) values(1, 199);
insert into order_items(order_id, product_id) values(1, 1153);
insert into order_items(order_id, product_id) values(1, 792);
What happens if the last insert fails? The database is left in an inconsistent state because these operations were not executed as a single atomic unit.
In relational databases, transactions give us atomicity by “wrapping” queries and treating them as one unit:
start transaction;
insert into orders(user_id, amount) values(1, 199);
insert into order_items(order_id, product_id) values(1, 1153);
insert into order_items(order_id, product_id) values(1, 792);
commit;
These three queries are treated as one single atomic unit.
Right?
No.
For a long time, I thought if I use start transaction it’s somehow becomes atomic. But it’s not true. Let’s put an invalid value into the second insert:
insert into order_items(order_id, product_id) values("ysdf", 1153);
And now run all three queries in a transaction:
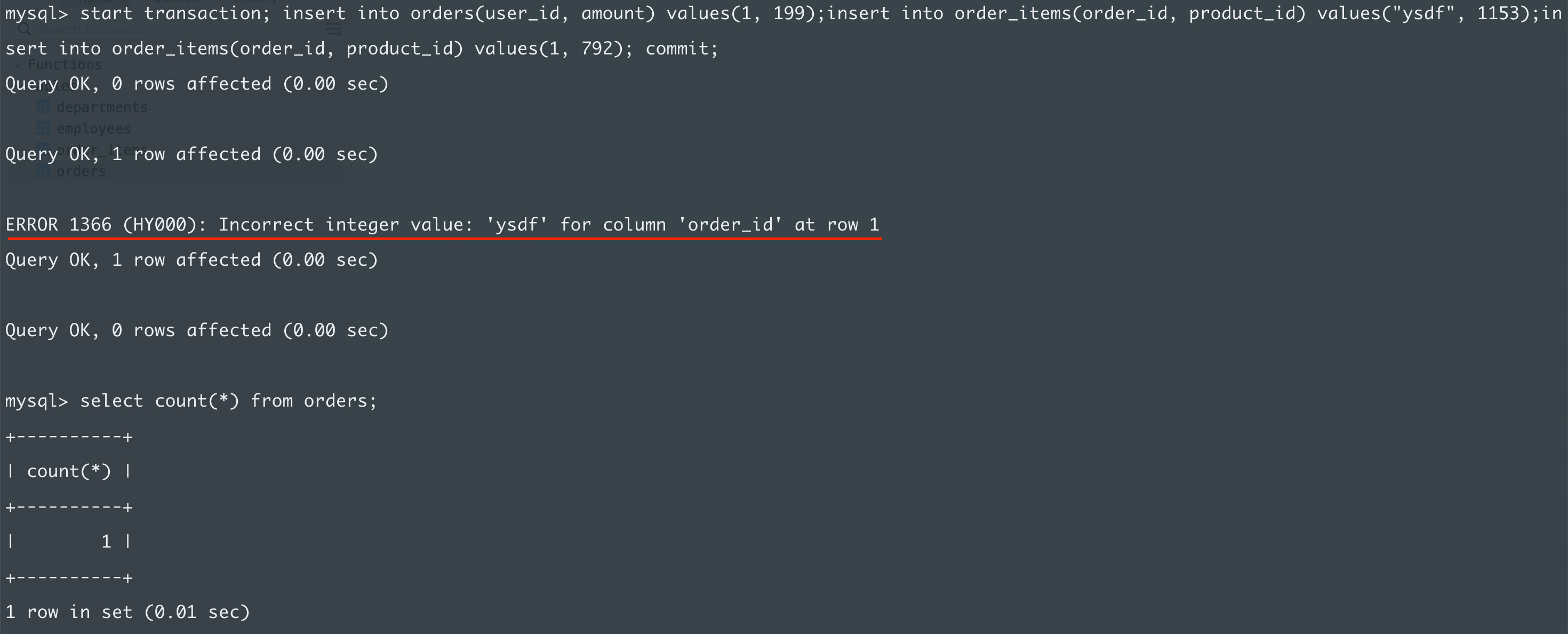
You can see logs like Query OK, 1 row affected. The first and the last insert statements are executed. Even though, there was an error in the middle, two rows were inserted.
In my experience, lots of developers think that if something fails the database is reverted back to its initial state by just adding a “start transaction:”
start transaction;
insert into orders(user_id, amount) values(1, 199);
insert into order_items(order_id, product_id) values(1, 1153);
insert into order_items(order_id, product_id) values(1, 792);
commit;
But we’ve seen that it’s not true. So let’s fix the query:
start transaction;
insert into orders(user_id, amount) values(1, 199);
if row_count() <= 0 then
rollback;
select "error while creating order";
show errors;
end if;
set @order_id = last_insert_id();
insert into order_items(order_id, product_id) values(@order_id, 1153);
if row_count() <= 0 then
rollback;
select "error while creating order item";
show errors;
end if;
insert into order_items(order_id, product_id) values(@order_id, 792);
if row_count() <= 0 then
rollback;
select "error while creating order item";
show errors;
end if;
commit;
select 'done';
We just found a language that’s error handling is more annoying then Golang’s
The missing piece was rollback. If you want full control over the state of your DB you need to check every operation and rollback if needed.
Usually, we handle these in the backend code instead of MySQL itself, but it's still interesting to look at it.
row_count() returns the number of affected rows by the last executed statement. It can be an insert or an update. Or a delete:

This guy is Hungarian, just as I
After each insert, we check if row_count() returns a value less than or equal to zero and we rollback.
Now these three queries are really form a single, atomic unit. Either all of them succeeds or none of them. Protecting the state of your DB.
But of course, usually we handle this in code:
public function store(Request $request, OrderService $orderService)
{
$order = DB::transaction(function () {
$order = $orderService->create(
$request->user(),
$request->amount,
);
foreach ($request->items as $item) {
$orderSerivce->addItem($order, $item);
}
return $order;
});
return OrderResource::make($order);
}
That’s it. An atomic “store” function. If an Exception is thrown the DB is reverted.
Consistency
Consistency is a little bit tricky.
It means that the DB transitions from one valid state to another valid state after a transaction.
The question is what is a “valid state” and how the DB can enforce it?
Foreign keys
One of the fundamentals concepts of a relational database is foreign keys. So use them. They ensure that only valid values can be inserted into a foreign key column. It enforces “valid state” in the context of relationships.
Unique constraints
Also a very important concept in relational databases. It guarantees that you don’t have duplicated data in a situation where you are not supposed to have duplicated data.
In my experience, people don’t use comopsite unique indexes enough. For example, take a look at this table called post_likes:
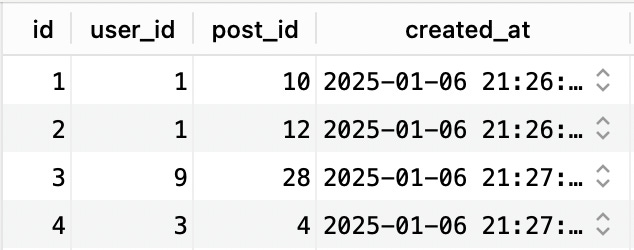
The user_id and post_id columns should be a unique composite index since one user can only like a post once:
create unique index `user_id_post_id_idx` on `post_likes` (`user_id`, `post_id`)
Data types and modifiers
It’s obvious that you cannot inert a string value into an integer column and it’s a good. But more importantly we can use data modifiers (such as unsigned) to enforce “valid state” and data integrity:
unsigned can be used to enforce basic business rules at the database level. For example, if you have a balance column that you execute additions and subtractions on, an unsigned modifier guarantess it always stays positive, even if you have a bug in your system.
varchar(100). Limiting the length of a column also ensures integrity and consistency even if your validation logic accepts an invalid string. The DB engine simply returns an error and rolls back the database.
NOT NULL guarantees you don’t have empty values in required columns.
Reasonable default values can also be very useful. For example, whenever I have a “status” or “state” column I also add the initial status as the defaul value:
create table orders (
id bigint unsigned primary key,
status varchar(32) default 'pending',
created_at timestamp default current_timestamp
);
check constraints The next one is sort a gray-area. You can do this in MySQL:
create table employees (
id bigint unsigned primary key,
name varchar(100) not null,
email varchar(100) check (email LIKE '%@%.%'),
age smallint CHECK (age between 18 and 65),
salary decimal(10,2) unsigned
department_id int check (department_id in (select id from departments)),
hire_date date check (hire_date > '2000-01-01')
);
You can basically write validation rules with the check keyword if you’re using MySQL8. This is useful, but it’s very “hidden.” Meaning, developers don’t naturally check the table definition for validation rules. They don’t accept the database to run e-mail validation rules, etc. (by the way, triggers have the same problem, in my opinion, so they are not included in this article). These checks are usually done by a framework or package on the HTTP level.
In some cases, however, I can see usefulnes in checks. Let’s say your app tracks some kind of balance. It can be negative, but only to a certain amount, let’s say -10,000 is the limit. If this is an important business rule, then I see value in doing this:
balance int not null check (balance >= -10000)
This should not be your only validation, of course. It should be your last “safety net.”
At the beginning, I said consistency is tricky. It’s tricky because it exists on two levels:
- Database
- Application
The DB can help you with these features but still need to handle at least thw following:
- Validate your data properly
- Handle errors properly
- Use transactions when it makes sense
- Use some locking mechanism (optimistic, pessimistic)
- Use audit logs or event streams. Or event sourcing.
- Regulary back up your system (database, redis, user uploaded files, .env files)
- Check data integrity and business rules
- If you have statuses and transitions you can use state machines, for example
- If you calculate something (such as a financial formula) you should assert the input variables
- Most of your API should be idempotent
- If you run a big migration and you delete an old table don’t actually delete the it. Just rename it to
orders_backup, for example. You can delete it later if the release was successful. - You can run periodic checks in certain cases. For example, a background job that check that balance column and notifies you if something went wrong.
- If you cache your data, always use a TTL (time-to-live) by default. Redis (or some other system) will automatically delete your key when the TTL passes. If you think 1 hour is a good TTL for a specific cache item, set it to 30 minutes by default.
The list goes on but we’re leaving the territory of database systems. Other techniques, such as defensive programming exists to defend you againts these kinds of errors.
Building a database engine
This whole article comes from my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:
Isolation
What happens if two DB clients accesses the same record at the same time and they both modify it in a different way?
Let’s do the classic counter example. There’s a table with a counter in it. The initial value is 10. Two clients (users) are trying update it at the same.
Let’s present this on an Enterprise-ready®, UML-based®, UncleBob-approved®, Agile®, Extreme®, Sequence Diagram® (ERUBUAAES® for short):
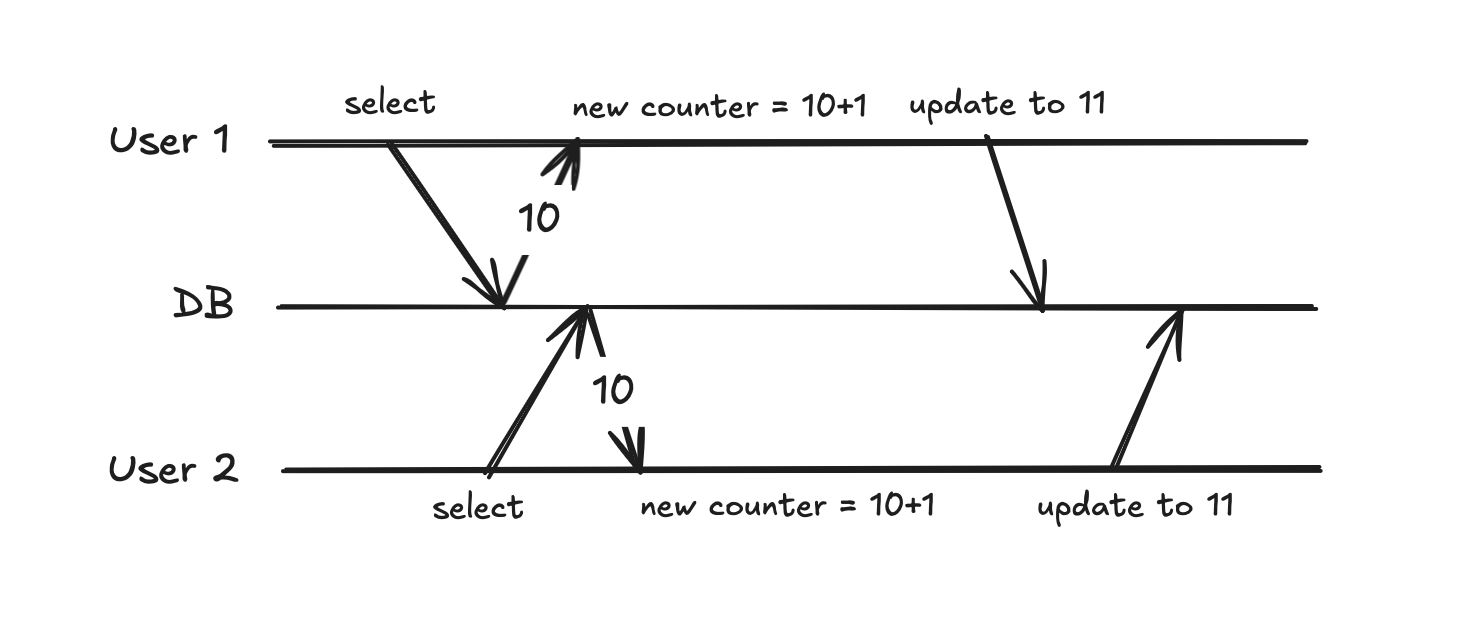
At the end, the new counter value in the database is 11 but it should be 12. This is called a race-condition and this is what happens:
- User 1 gets the value of the counter. Which is 10.
- At the same, or a few ms later User 2 also gets the counter value. Which is 10.
- User 1 increments the counter and updates it in the DB. It’s now 11.
- User 2 does exactly the same.
So isolation deals with concurrency. And this problem is not unique to databases. The same can happen in your goroutines if you don’t use mutexes.
The question is: what should happen in the above situation? Before answering the question, let’s talk about:
- Dirty reads
- Non-repeatable reads
- Phantom reads
Dirty reads
A dirty read happens when a transaction reads data that hasn't been committed yet by another transaction. (In this context, transaction, user, client refer to the same thing.)
This is exactly what happened in the above situation. When User 2 read the counter the DB returned 10 but User 1’s transaction was not commited yet.
We can prevent dirty reads by making User 2 wait until User 1 commits the transaction:
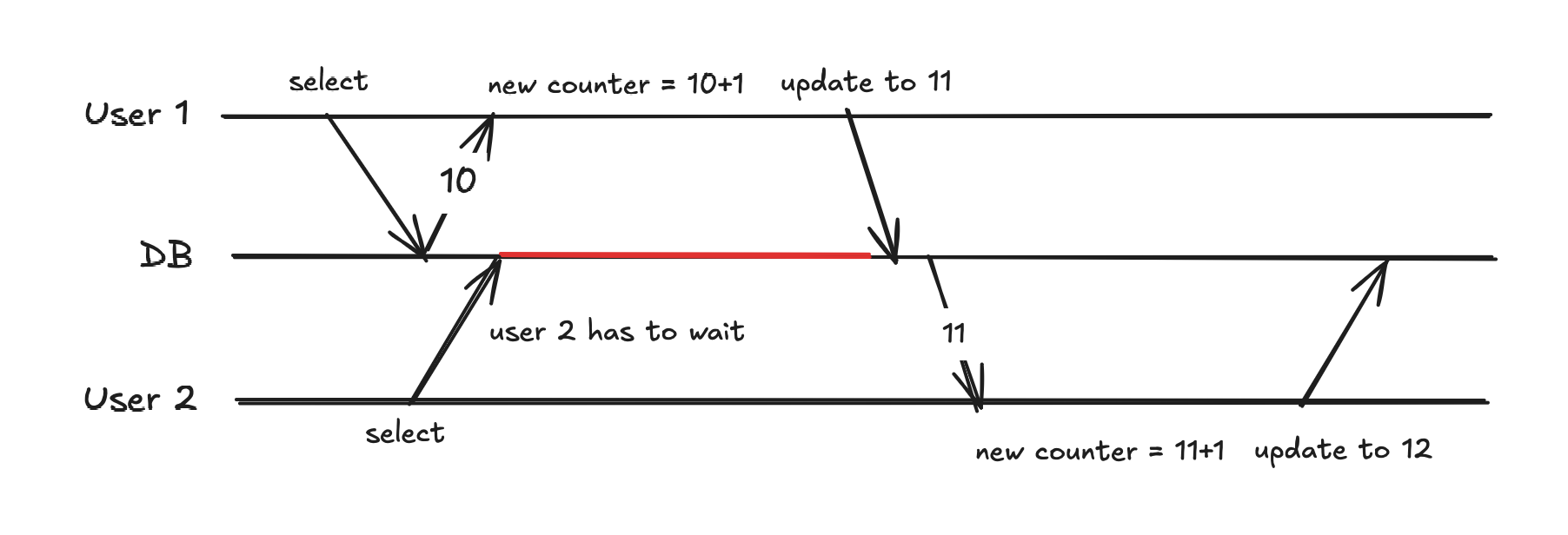
The red line represents a period of time when User 2 is blocked. It has two wait until User 1 either commits or rolls back its changes.
Previously, the counter was updated to 11 by User 2. Now it is 12 as it should be.
An even worse situation would be this:
/* counter is 10 at the beginning */
User 1: update counter set counter = 11;
User 2: select counter from counter; -- Reads 11
User 1: rollback;
User 2: update counter set counter = 12;
The counter mistakenly went from 10 to 12 because User 1 did a rollback.
Non-repeatable reads
It happens when a transaction reads the same row twice and gets different data each time:
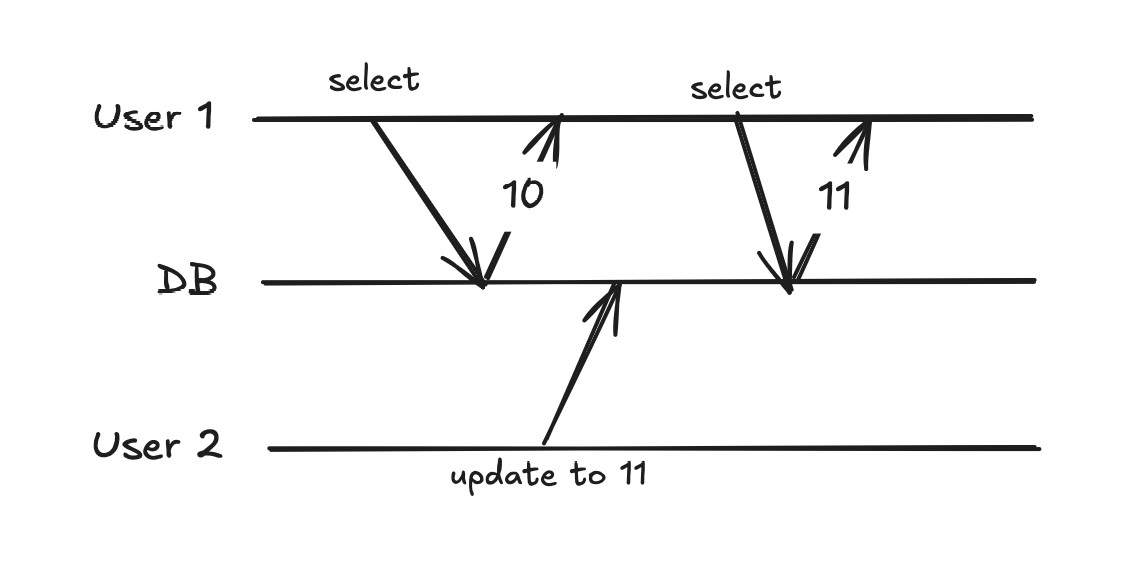
Given the fact that User 1 runs the two queries in one transaction this should not happen in most cases. Once again, User 2 should be blocked until User 1 is done:
Once again, the red line represents a period of time when User 2 is blocked.
Phantom reads
Phantom read is almost the same as a non-repeatable with only one difference:
- Non-repeatable reads involve changes to existing rows (the counter was updated)
- Phantom reads involve the addition or removal of rows that match a query's criteria
So a phantom read has a similar effect and it looks like this:
User 1: select count(*) from accounts where balance > 10; -- Returns 5
User 2: insert into accounts (balance) VALUES (11);
User 2: commit;
User 1: select count(*) from accounts where balance > 10; -- Returns 6
The same in the same transaction return different data. But not because the existing data was changed but new records were inserted.
Summary:
- Dirty reads involve uncommitted data
- Non-repeatable reads involve changes to existing rows
- Phantom reads involve the addition or removal of rows that match a query's criteria
Now that we actually know the different concurrency problems and we have fancy names for them let’s solve them.
I started this chapter with a question: what should happen in the above situation? (the above situation refers to the first ERUBUAAES® diagram).
And the answer is: almost anything can happen depending on the isolation level of your MySQL server. There are four different settings with four different behaviors:
- Read uncommitted
- Read committed
- Repeatable read
- Serializeable
These isolation levels control what should happen in the above situations. They control how concurrency problems and race conditions should be resolved.
### Read uncommitted This is the lowest isolation level. Transactions can read data that has not yet been committed by other transactions.
It allows:
- Dirty reads
- Non-repeatable reads
- Rhantom reads
It prevents none of the problems. Basically, anything can happen in your database. You should not use it unless you have a very good reason.
Read committed
This is a stricter isolation level.
It prevents:
- Dirty reads.
Each SELECT sees only data committed before the query began.
But it still allows:
- Non-repeatable reads
- Rhantom reads
This is also a “dangerous” isolation level and you probably should not use it unless you have a very good reason.
Repeatable read - The default
This is an even stricter level and is the default in MySQL.
It prevents:
- Dirty reads
- Non-repeatable reads
But it still allows:
- Phantom reads
Why does the default configuration allows phantom reads? As far as I know, it’s mainly a trade-off betweemn consistency and performance.
I don’t know the exact implementation details, but to the best of my knowledge repeatable read works like this:
- When a read happens in the transaction it places a lock on the selected rows.
- However, the query reads from an index. And it doesn’t lock rows in-between your rows. This is called a “gap.” If you’re not sure what “rows in-between your rows” mean, check out this article about database indexing.
- So these “gaps” aren’t locked. Because of that, other transactions can insert new rows into the range of your query criteria.
It also envolves snapshot creation. It’s quite complicated. Please don’t qoute me on that.
Serializeable
This is the most strict isolation level.
It prevents:
- Dirty reads
- Non-repeatable reads
- Phantom reads
This is the most consistent level of all. On the other hand, this is the slowest one.
There are certain use cases when it is a good fit and worth the trade-off, for example:
- Healthcare systems, where data accuracy can have life-or-death implications
- Financial applications. Banks, trading apps, payment processors. Every transaction must be accurate and consistent.
- Reservation systems. Overbooking must be strictly prevented
To change your isolation level, run this command:
set session trandsaction isolation level read committed;
Durability
Durability guarantees that once a transaction has been committed, its changes are permanent and will survive system failures.
In a non-distributed environment (such as when you start a mysql process) it means that your data is written to the disk.
On top of that, most DB systems use some kind of write-ahead log (WAL) mechanism to prevent data loss in the event of a system failure.
The fundamental principle of WAL is that changes are written to a log before they are applied to the database itself. This log is stored on disk and is used to recover the database in case of crashes. SQLite does this, MySQL does this, Redis does this (in the form of an append-only log), Postgres does this.
Another interesting aspect of WAL is that it helps improving performance. Because every change is written to a log file, the table file (the file where your database system store your table’s data) doesn’t need to be modified each time an operation is executed.
If you’re interested in databases, don’t forget to check out my new book:
Building a database engine
This whole article comes from my book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out: