« back published by Martin Joo on February 25, 2025
How does MySQL store your data?
In the last 13 years, I've used many programming languages, frameworks, tools, etc. One thing became clear: relational databases outlive every tech stack.
Let's understand them!
Building a database engine
Even better. What about building a database engine?
In fact, I've already done that. And wrote a book called Building a database engine.
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:

The following is part of the first chapter of the book.
A naive approach
One of the most important thing about a database storage engine is the storage format.
We are all used to a CSV or Excel-type format when it comes to data. If you open any database GUI you see tables like this one:

Since MySQL, Postgres, or SQLite are column-based, relational databases it seems logical to store the data in a CSV-like format.
id;name\n
1;my_pod\n
2;pod2\n
3;another_pod\n
This represents a simple table like this:
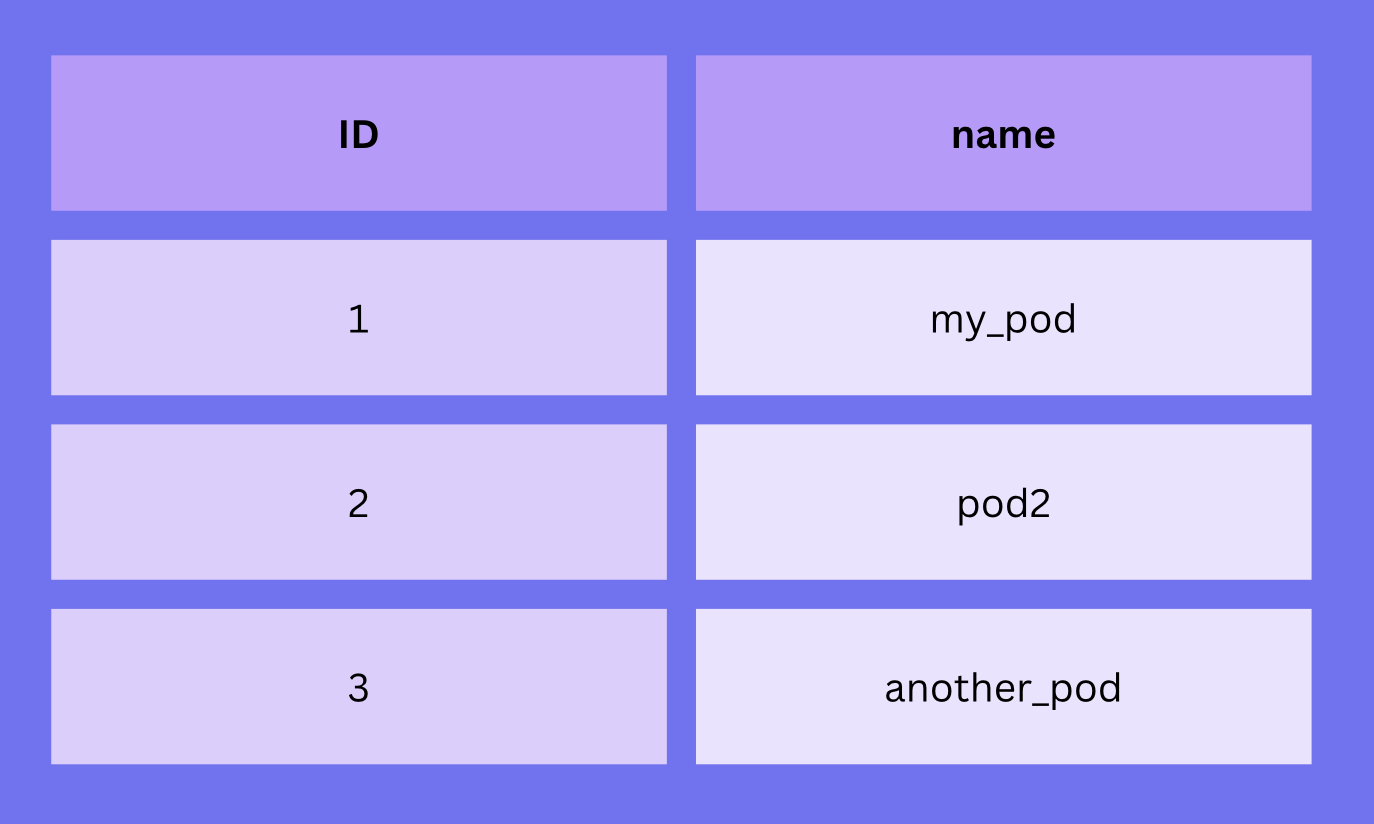
Without involving any database-related topic, how would you find the second row in this table? Imagine if this was the content of a simple string. How would you write the code to find row #2?
I'd write something like this (in an imaginary language):
content = "1;my_pod\n2;pod2\n3;another_pod\n"
for (i = 0; i < len(content); i++) {
c = content[i]
if c == "\n" {
continue;
}
// here, we know that the next character is the primary key
if c == "2" {
return "match"
}
// if not a match, seek to the end of the row
while c != "\n" {
i++
c = content[i]
}
}
This is extremely naive and probabaly would not work. But the point is that a separator-based storage is very slow.
The engine doesn't know the length of the rows, or the length of individual columns so it iterates through the whole table byte-by-byte. This is called O(n) or linear time complexity and it's not acceptable in a database engine.
If your table is 500MB (which is not that large), this loop can run up to 500,000,000 iterations.
The main problem is that the engine doesn't know the length of the data. Let's fix it.
Delimiters can be removed by having fixed-siz rows. name if fixed to 16-bytes:
1my_pod..........
2pod2............
3another_pod.....
. characters represent empty bytes. Having fixed-size rows it's the same as right padding the values:
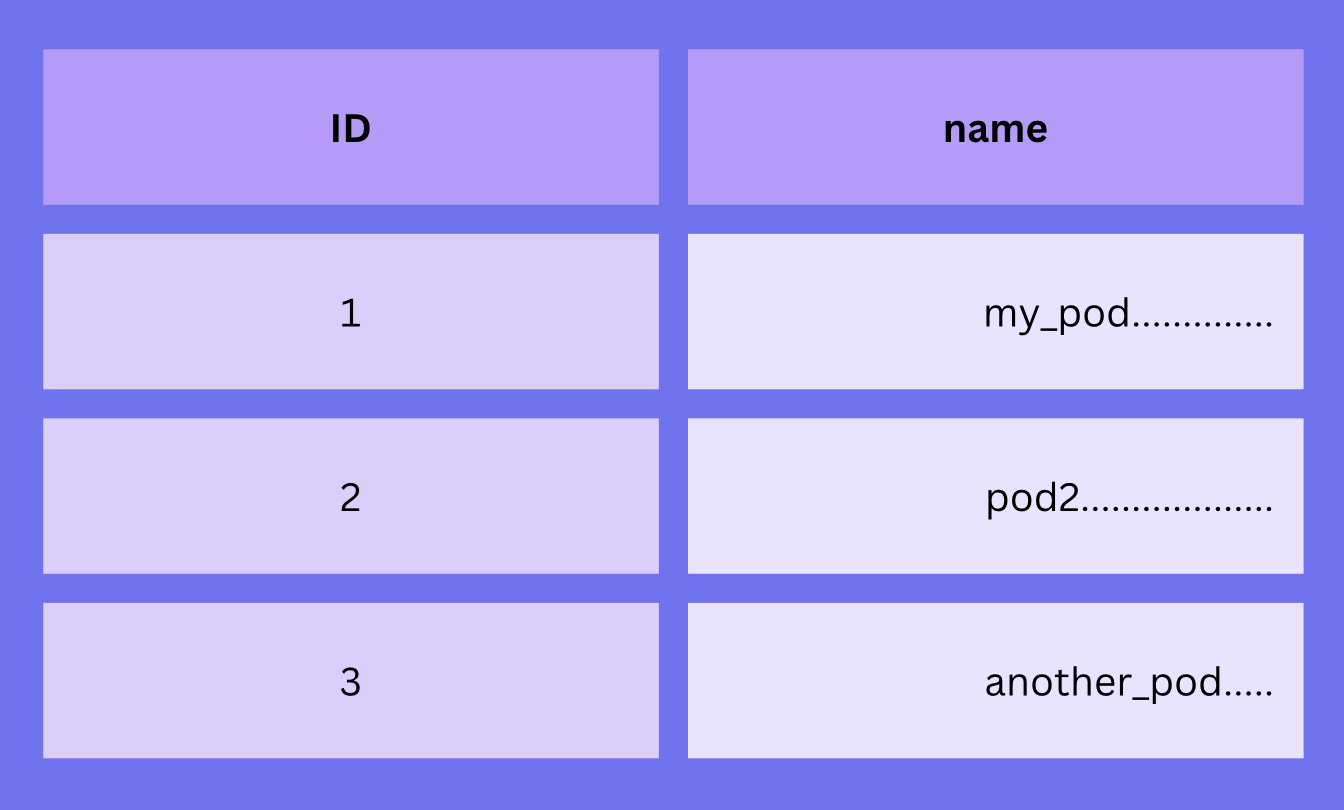
This is just a toy example, so we treat the IDs as if they were characters. For now, they always take 1 byte and they are characters.
If the fix size of the name column is 16 bytes then every row is exactly 17 bytes long. This is a big improvement, because now we can write a much better algorithm:
content = "1my_pod..........2pod2............3another_pod....."
for (i = 0; i < len(content); i++) {
if c == "2" {
return "match"
}
i += 16 // This is the big improvement
}
The loop now can scan the table row-by-row instead of byte-by-byte. This is a huge improvement.
For testing purposes, I created a table with 4 million rows. It's 640MB.
- Byte-by-byte algorithm: 640,000,000 possible iterations
- Row-by-row algorithm: 4,000,000 possible iterations
The difference is 160x
But the fixed-size version has a big disadvantage, too. In real database systems, the size of a text-based column is not 16 bytes but:
- 255 bytes for
varchar - 65,535 bytes for
text - 16,777,215 bytes for
mediumtext - 4,294,967,295 bytes for
longtext
Imagine a mediumtext column:
1this is a mediumtext column and we do not know where it ends........
2maybe it is short...................................................
3maybe it is 10 million characters long...............................
If you know the next 16 million characters contain your text, but you don't know how long the actual text is, what would you do?
I'd do something like this:
content = "maybe it is 10 million characters long..............."
usefulContent = ""
for i = 0; i < len(content); i++ {
// zero byte is represented by '.' now
if content[i] == '.' {
break
}
usefulContent += content[i]
}
This is a linear algorithm again. We possibly run millions of iterations to get only one column.
Yes, you can run a variation of binary search to get the first position where there's useful content in O(logN) time but you still don't know how many extra iteration is needed after the starting point.
We can fix this problem by adding the length of the string to the file:
16my_pod..........
24pod2............
38your_pod........
The numbers 6, 4, and 8 mean that the next column contains 6, 4, and 8 bytes.
The table now contains an additional "meta column":
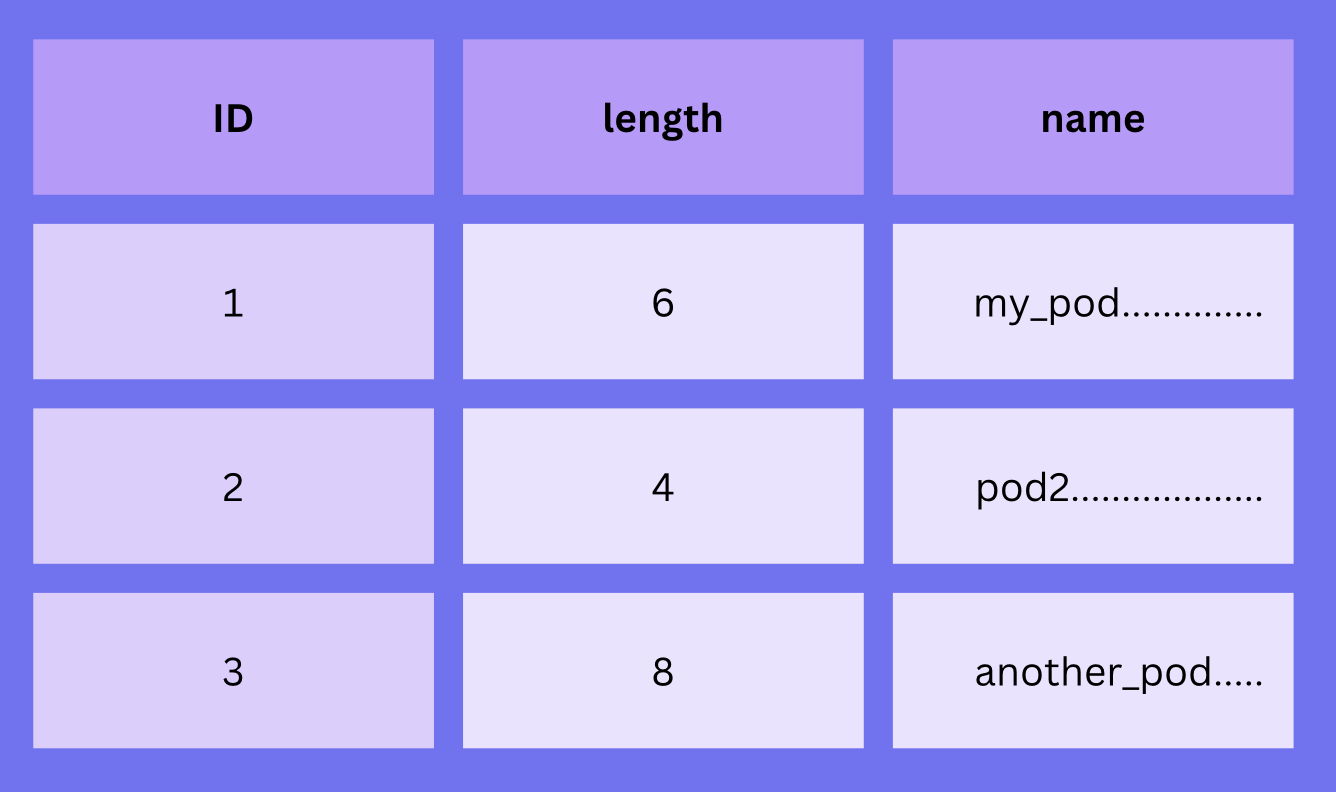
Searching is the same as before since rows still have fixed sizes. But now the actual data can be read in one operation since we know its size:
row = "16my_pod........"
length = 6 // we already read this information
data = row[2:2+length] // read from position 2 until we have useful content
In one operation, the whole string can be read because the engine knows its length.
Searching is now faster, but it still has a huge drawback. Fixed-size data wastes a lot of space. And it's not acceptable in a real DB system.
Just think about a mediumtext column. What if your table has 1,000,000 columns and the engine allocates 16,777,215 bytes or 16.78MB for each column? This single column would take up to 16,780,000MB or 16,780GB or 16.78TB of storage. Obviously, we don't want to risk bankruptcy because of one column.
Fortunately, we've already seen the solution: store the length and make everything variable-length.
16my_pod
24pod2
38your_pod
Names don't need to be aligned anymore:
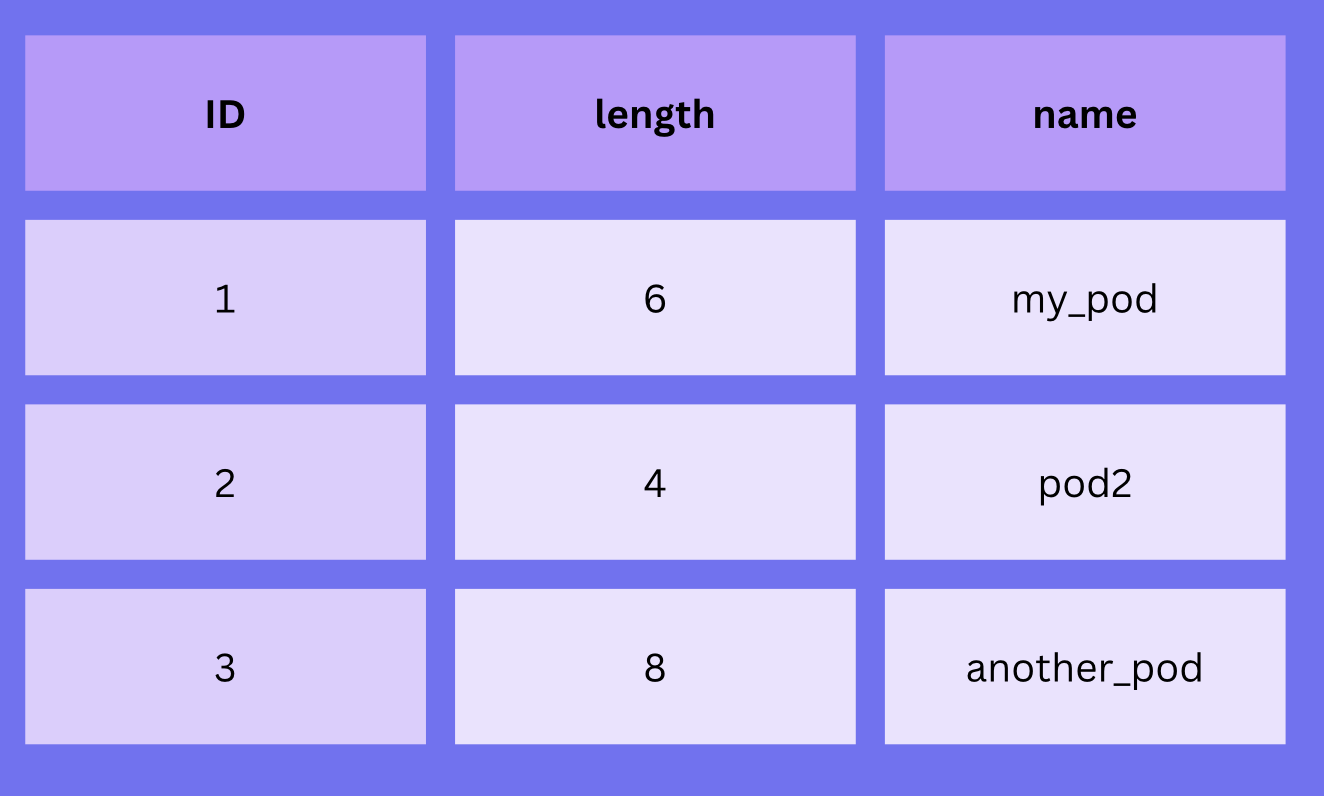
Now it's easy to read the content:
- The first number is the ID
- The second one is the length of the string
- And the string itself which takes only
lengthbytes
When reading the length (such as 4) the algorithm needs to read length number of bytes to read the entire string or to skip it and continue with the next row.
Here's an oversimplified algorithm that collects the IDs:
content = "16my_pod24pod2"
ids = []
i = 0
for {
// In the first iteration it's "1"
ids[] = content[i]
// Jump to the length
i++
// In the first iteration it's "6"
length = content[i]
// Skip the name
i += length
// Break if there are no more records
if i > len(content) {
break
}
}
In two iterations, it collects the two IDs.
In these examples, I treated everything as characters and strings, but the real world is more complex than this. So let's make it more real.
Building a database engine
This whole article comes from my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:
TLV (Type-Length-Value)
TLV is an encoding schema and is extensively used in lower-level computer science topics:
- Databases
- Network protocols such as TCP, HTTP, proto buffers
- Cryptography
- Bluetooth and other standards
- Financial systems use similar encodings defined in ISO 8583
- CAN in the automotive industry is based on a similar encoding
- etc
Say we want to encode integers and strings in a language, OS, and platform agnostic way. First, we need to associate different data types with arbitrary flags, for example:
| Arbitrary flag | Type |
|---|---|
| 1 | integer |
| 2 | string |
Whenever I say "1" you know it's an integer.
This is the letter T in TLV.
The next letter is L for length. We've already used it earlier. An integer is 8 byte on a 64bit system.
1 8
In TLV, this reads as:
- The next value is an integer. Because 1 means integer.
- It's 8byte in length.
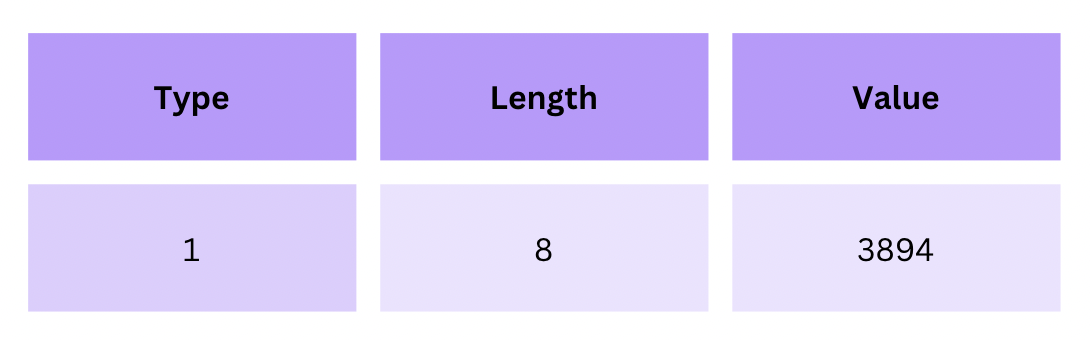
The last letter is V for value:
1 8 3894
1for integer8for 8 bytes3894for the actual value
The 8-byte number 3894 looks like this in TLV:
Integer numbers are going to be represented in little-endian binary foramt, later. For now, it's easier to just think them as simple numbers taking up 8 bytes of space.
For strings, we reserved type 2:
2 5 hello
Let's take this table as an example:

The TLV encoded version would be this:
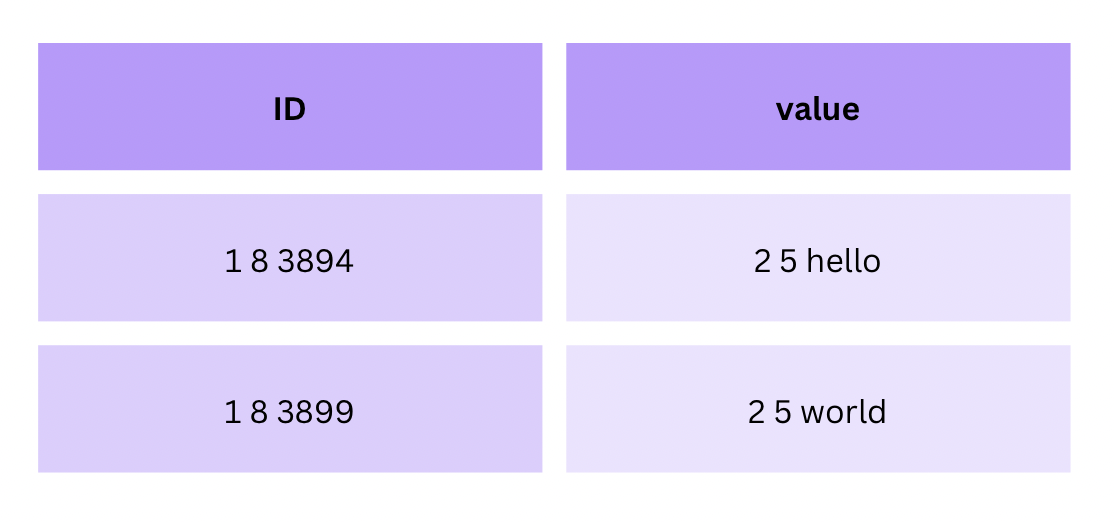
If a table has an ID and a string column, a row would look like this:
1 8 3894 2 5 hello
Now an algorithm can easily jump between columns.
But what about jumping between rows?
1 8 3894 2 5 hello
1 8 3899 2 5 world
(Of course, there are no new line separator between the rows. But this way it's easier to read)
To find the second row we still need to:
- Read the type of the first row (1)
- Read the length of the first row (8)
- Read the ID of the first row (3894)
- Check if that's what we're looking for. It's not.
This process looks like this:
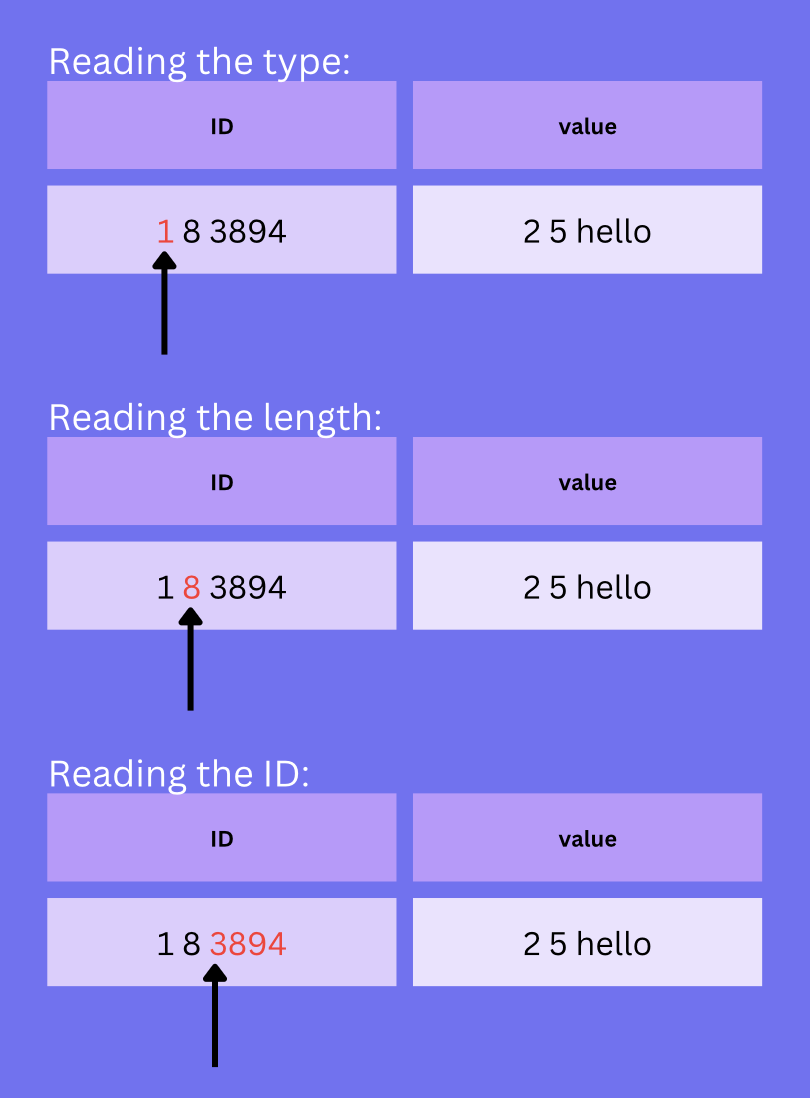
But it's not finished yet. It continues with these steps:
- Read the next type byte (2)
- Read the length byte (5)
- Skip 5 bytes
It also iterates through the value column:

At this point, it skipped the first row. It continues with the second one:
- Read the type (1)
- Read the length (8)
- Read the ID (3899)
- Check if that's what we're looking for
- Done
This still involves lots of unnecessary steps. The algorithm needs to read the first row column-by-column.
Why?
Becuase there's no better way to know where a record ends and where a new one starts.
This is not acceptable in a real DB.
To solve this, we can come up with a new type. A type that represents an entire row. So we extend the type-table:
| Arbitrary flag | Type |
|---|---|
| 1 | integer |
| 2 | string |
| 100 | row |
An entire row can be represented as:
100for typeXfor the length, which equals to the length of all columns in the given rowXfor value, which is the entire row represented as another TLV encoded value. So a row is going to be a recursive TLV record.
You can imagine a record like this:
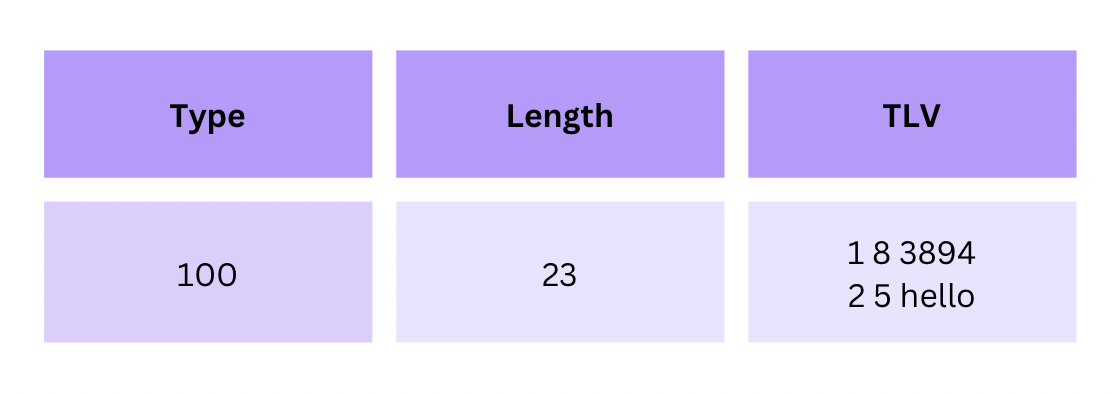
The last column (Value) represents the record with the integer and string columns discussed earlier. The value field contains another TLV record.
The two example records can be represented like this:
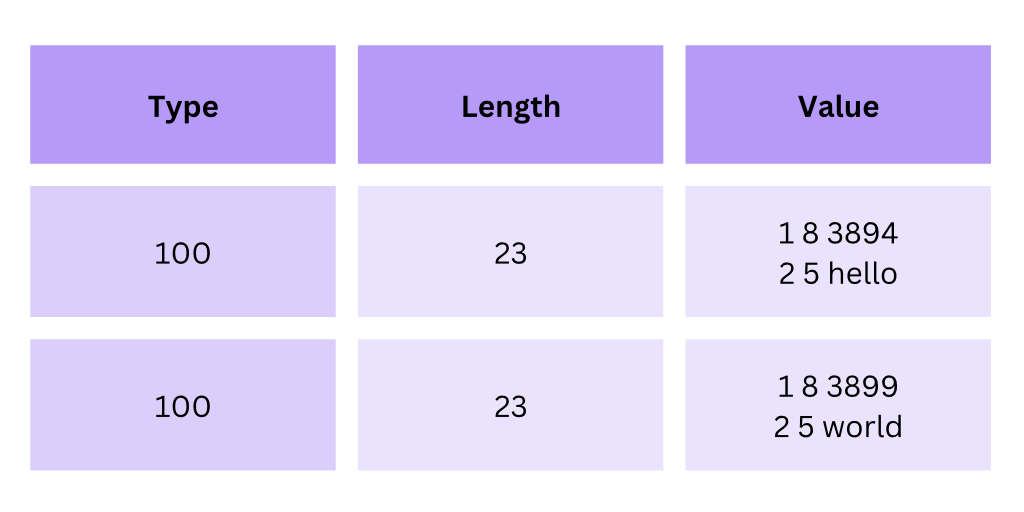
In order to add this new type, we need to know the length of a record:
1 8 3894 2 5 hello
In the previous chapter, I used the term "character" a lot. It was just a simplified example.
In the real world, this file is binary encoded. It stores bytes. Don't confuse character length with byte length, for example:
49999 can be expressed using 5 characters but it takes up only 2 bytes as a number. In a binary encoded file, 49999 is expressed on 2 bytes. In these examples, it's using 5 characters, but don't let this confuse you.
For the sake of simplicirty, I'm assuming ASCII encoding when it comes to strings. Each character is 1 byte.
What about the type flags, such as 1, 2, or 100?
Since these values are arbitrary, we can define their size. I don't think we need more than 256 types, so 1 byte is enough.
If we take this example again:
1 8 3894 2 5 hello
We know the following:
| Value | Length |
|---|---|
| 1, the type flag for integers | 1 byte |
| 3894, the integer value | 8 bytes |
| 2, the type flag for strings | 1 byte |
| hello, the string value | 5 bytes |
The only missing pieces are 8, and 5 the length fields for the integer and string values.
This is also arbitrary. If you want to support longtext with 4 billiion characters, you need 8 bytes.
For now, let's use 4 bytes for expressing the length of a value.
The extended table looks like this:
| Value | Length |
|---|---|
| 1, the type flag for integers | 1 byte |
| 8, the length of the integer | 4 bytes |
| 3894, the integer value | 8 bytes |
| 2, the type flag for strings | 1 byte |
| 5, the length of the string | 4 bytes |
| hello, the string value | 5 byte |
| Overall length of the row | 23 bytes |
The overall size to represents this row:
| ID | Value |
|---|---|
| 3894 | hello |
is 23 bytes.
13 bytes for the data and 10 bytes for metadata. In fact, the meta data required by one TLV is always 5 additional bytes:
- 1 byte for the type (T) flag
- 4 bytes for the length (L) flag
Since the record has two columns (two TLV values), metadata takes 10 bytes.
In this system, an integer is always 8+5=13 bytes and a string is always 5+len(str) bytes.
Finally, we can add the new "record" type:
100 23 1 8 3894 2 5 hello
100 37 1 8 3899 2 19 my name is not john
Finding ID 3899 is much easier now:
- Read the type flag (100)
- Read the length (23)
- Read the type of the ID (1)
- Read the length of the ID (8)
- Read the ID (3894)
- Is it 3899?
- If not, skip
23-(length of the ID column)bytes
The process visualized:

In the last step it skips 23-x bytes, where x is the number of bytes it already processed:

Using a format like this, doesn't require the engine to scan each column if it wants to skip a row. From the 100 type flag and the 23 length value it knows exactly how to skip an entire row.
This format is quite efficient for two reasons:
- Easy to skip entire rows
- Space efficient because everything is variable-length
Real database engines use more compact formats to save space but they are all based on this basic TLV encoding.
Building a database engine
This whole article comes from my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out: