« back published by Martin Joo on February 20, 2025
Query Optimization 101
In the last 13 years, I've used many programming languages, frameworks, tools, etc. One thing became clear: relational databases outlive every tech stack.
Let's understand them!
Building a database engine
Even better. What about building a database engine?
In fact, I've already done that. And wrote a book called Building a database engine.
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:

Access types
The quickest way to identify inneficient queries is to check your slow query log file and/or run EXPLAIN queries:
explain select * from users where id = 10
The most important thing in the output is the acces type.
ALL is the worst possible value. It’s also known as full table scan. It means MySQL reads the whole table from disk and processes it. It’s usually a sign of a missing index.
Index is the second worst value. The name “index” looks promising but it actually means that the DB engine needs to traverse and read the whole BTREE index. If you have 500k in your table (whick is not a lot) it’s 500k iterations.
Even worse, if the Extra column doesn’t contain Using index it means that you’re practically doing a full table scan. In this case, the query is not just traversing through the whole tree, but it also executes I/O operations to get the data from disk. Usually happens when you have a “select *” so the required data cannot be served using the index.
Range is great. It means that the engine is able to identify a range of BTREE nodes and it only has to traverse through them. Usually happens when you have a between or <> in your query.
But once again, if the Extra column doesn’t contain Using index it means MySQL executes unnecessary I/O reads to get the data. Look out for those select * statements in important queries!
const or ref means your query is as good as it can be.
Number of rows/filtered rows
EXPLAIN’s output contains two interesting columns:
- rows
- filtered
rows means how many rows the query engine has to iterate over to execute your query.
filtered means what percentage of those rows are actually returned to you.
Here’s an example:

Rows is 390, and filtered is 11.11 which means:
- MySQL uses the index to get 390 rows
- These 390 rows have to be checked against the where expression
- MySQL estimates that only 11.11% of the rows will remain in the result.
This means about 43 records. In order to filter out 43 records it had to go through 390 rows. This is far from optimal. MySQL has to load, loop through, and discard 88.89% of your table in order to return 11.11% of it to you. Imagine if the table has 1,500,000 rows.
Here’s a quick rule: a low “filtered” number means the query is inefficient. Also, a high “rows” number can be a sign of a bad index.
These numbers are usually related to composite indexes and column cardinality. I wrote about these topics in great detail here.
Select *
I already mentioned that select * can ruin the execution plan usually because:
- You create an index with two columns
- You run a select * query
- Explain says it’s an “index” type without “Using index”
Because your index contains only two columns, but your query needs 19 the DB has to execute many unnecessary I/O reads.
select * can be the difference between traversing a BTREE and executing thousands of extra I/O operations. Here are some things about select *:
- Index usage. As we discovered it may prevent the optimizer from utilizing indexes efficiently.
- Network traffic. MySQL connections are simple TCP (network) connections. When you retrieve every column vs just a few ones the difference can be big in size which makes TCP connections heavier and slower.
- Resource consumption. Fetching everything from disk just simply uses more CPU and memory as well. The worst case scenario is when you don't need all the data and the query (without select *) could have been served using only the index. In this case, the difference is "order of magnitudes."
And let’s be honest. Usually, you don’t need all the columns.
## Text columns and LIKE %
A BTREE node in an in dex can store 4KB of data (the page size in OS). It means you cannot store a mediumtext, or longtext column in a BTREE index:
create index content_idx on episodes(content)
Query 1 ERROR at Line 1: : BLOB/TEXT column 'content' used in key specification without a key length
It says we need to specify a key length:
create index content_idx on episodes(content(768))
Query 1 OK: 0 rows affected
This means we can only index the first 768 characters of a mediumtext column.
Did you know that a mediumtext column can hold 16MB of data? It’s 16,777,216 bytes. But we can only index 768 of those.
Although, it technically works, it usually results in very very slow queries, for example:
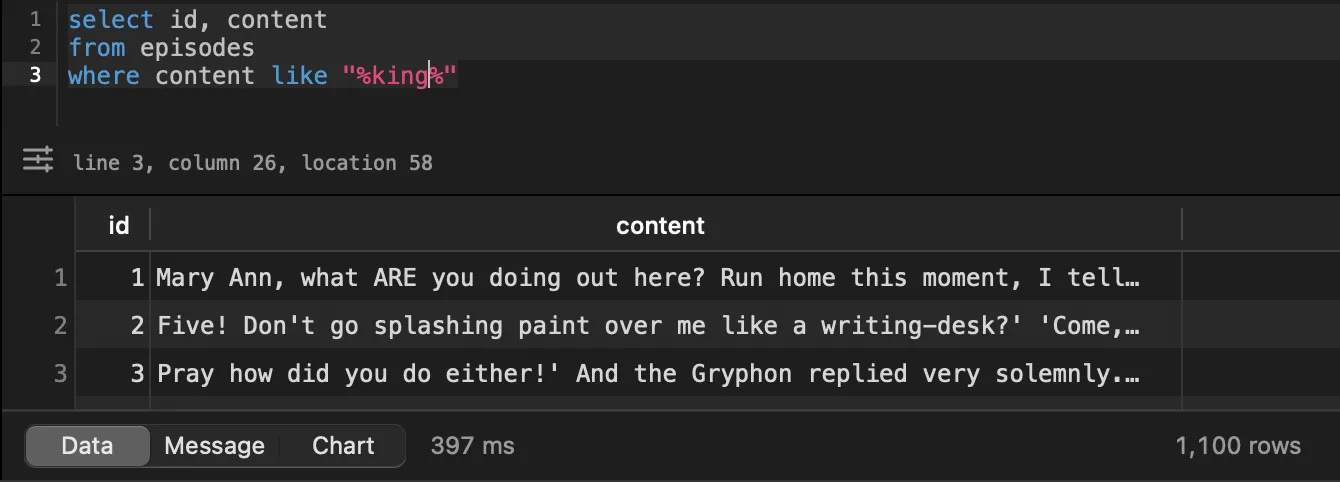
This table has only 1,100 rows and the query took 397ms.
If you want to use larger text column to implement autocomplete or search features use full-text indexes.
## Full-text indexes
Without getting into details MySQL offers full-text indexes and full-text search that is good for:
- Storing large text efficiently
- Running query similar to LIKE % effectively
For example, the previous (very slow) query can be done like this:
select
id,
title,
match (content) against('king*' in natural language mode) as relevance
from episodes
where match (content) against('king*' in natural language mode)
order by relevance desc
And it takes only 25ms:
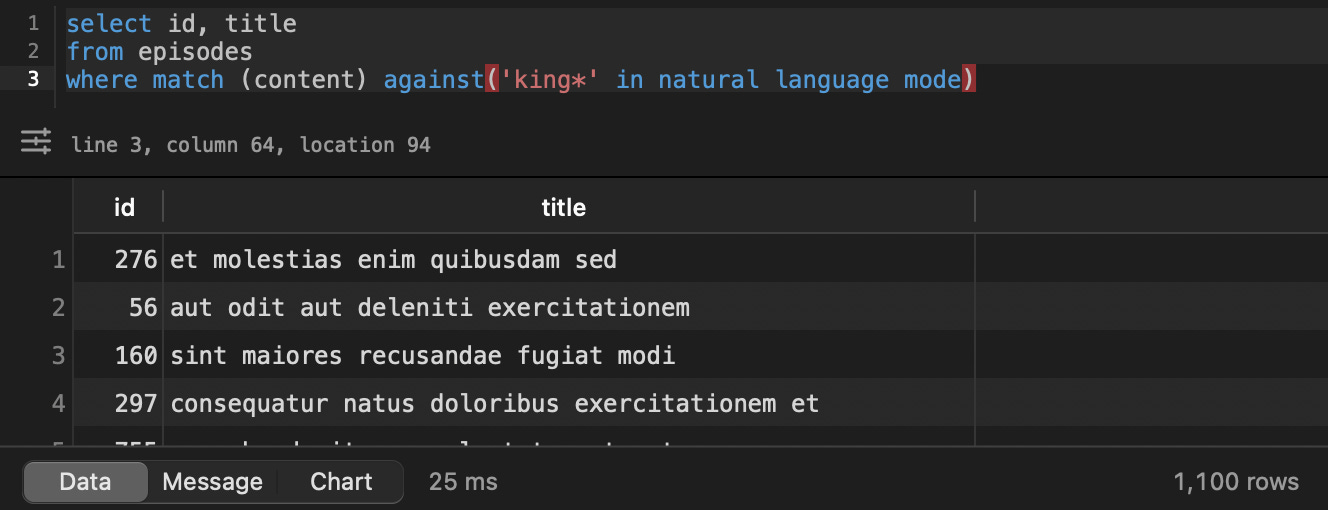
The difference is 16x
I wrote about this topic in great detail in this post.
Building a database engine
This whole article comes from my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out:
JOIN order matters
JOIN order can matter in a query. Here’s why:
select *
from users
join post_views on post_views.user_id = users.id
join post_likes
on post_likes.user_id = users.id
and post_likes.post_id = post_views.post_id
and post_views.post_id in (...)
This query returns users who have viewed and liked certain posts.
Let’s assume that an average post has more views than likes. In my experience, the ratio is between 100x-500x. Viral posts are more closer to 50x-100x but an average post has something like 200 views for every like.
So the post_views table has substantially more records than the post_likes. Let’s say post_views has 10,000 records for the given users and posts_likes has 100 records. This means we don’t need more records than 100.
In the first JOIN, we make MySQL to load 10,000 rows just to discard 9,900 of them in the second JOIN.
You can imagin this like an array of 10,000 items and for loop that loads another array with 100 items and finds the intersection:
$10k_rows = [...];
$100_rows = [...];
foreach ($10k_rows as $row) {
if (!in_array($row, $100_rows)) {
continue;
}
}
For a moment, forget about in_array. Let’s assume, it’s magic and it works in O(1) complexity. So this loop results in 10,000 iterations and returns less than 100 rows.
Obviously, you would write the loop this way:
$10k_rows = [...];
$100_rows = [...];
foreach ($100_rows as $row) {
if (!in_array($row, $10k_rows)) {
continue;
}
}
Again, let’s assume in_array is magic. This loop results in 100 iterations and returns less than 100 rows.
The reason I said in_array is magic because it’s an analogy to JOIN in MySQL which I believe is pretty smart and optimized.
This is a very similar problem to cardinality and rows vs filtered rows.
After so many examples, we can arrive to a conclusion: the best way to work with big datasets is to avoid loading big datasets at all. Always try to divide and conquer.
Subquery in SELECT
I’m talking about this:
select
users.id,
(
select count(*) from products
) as foo
from users
The select statement has another select. Not good.
This might result in an N+1 query problem at the database level. Yeah, it turns you don’t even need an ORM to have N+1 queries.
First, MySQL loads the users. Then it executes an additional query for each row. So if you have 1,000 users you’ll end up with 1,001 queries.
Most DB engines are smart, and I believe this specific example won’t run addtional query for each record because select count(*) from products can be cached pretty easily. But what happens if the subquery depends on the current row?
It can also hurt your index usage since subqueries and functions cannot be stored in an index (in PostgreSQL there are functional indexes).
Composite indexes
I wrote about this topic in great detail here.
But here’s the executive summary for you.
You can imagin an index like a table:
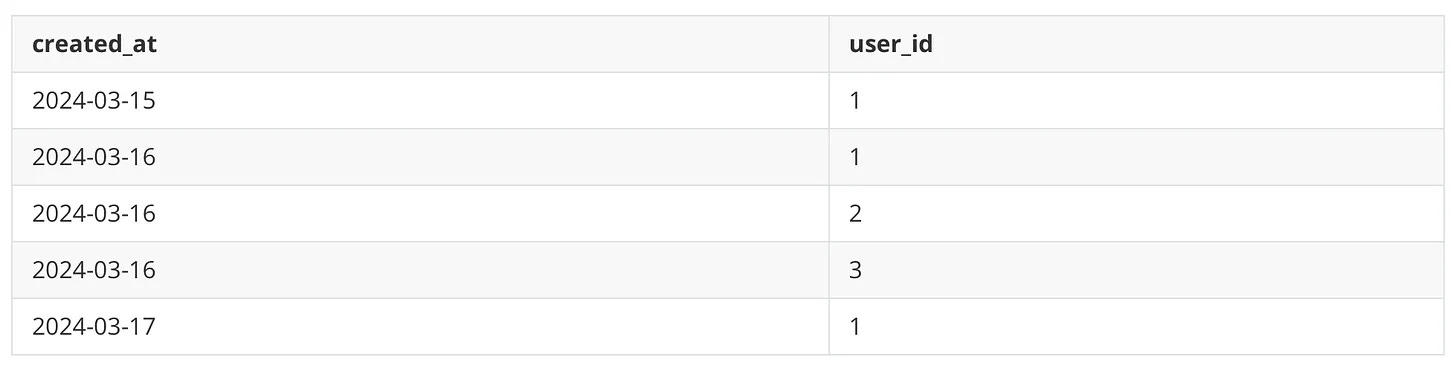
This index contains the created_at and the user_id columns in this order.
As you can see, the index (the table) is only really ordered by created_at. user_id is only ordered in relation to created_at. Just look at the value 1.
Imagine this query:
where created_at between "2024-03-01" and "2024-03-30"
and user_id = 1
From the example table above the DB engine needs to go through every row just to select the 3 important ones. Because every created_at is in March.
What happens if we switch the columns?
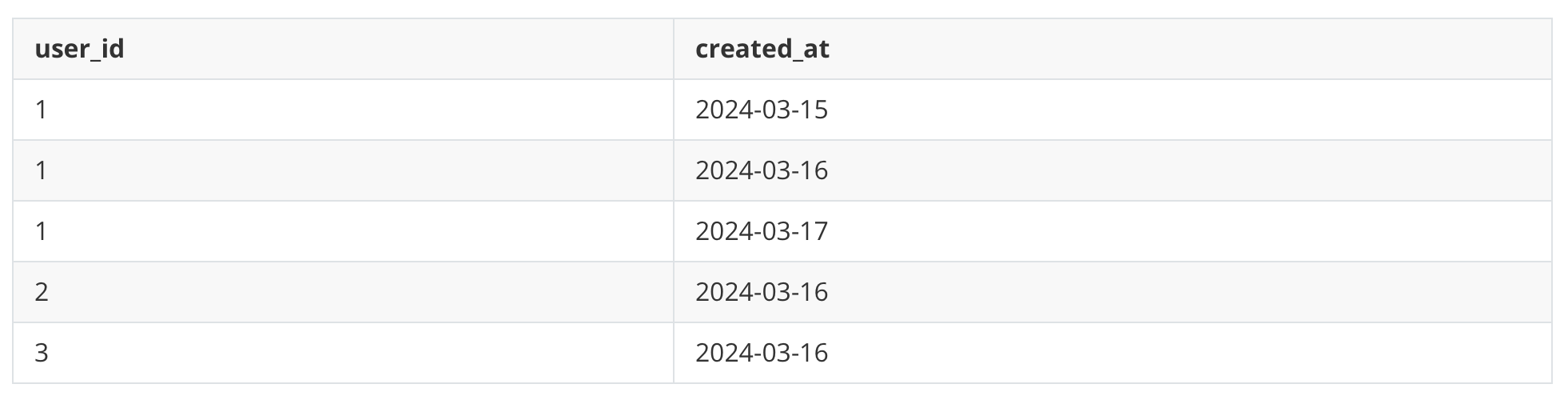
The same query again can filter the first 3 rows based on the user_id in the query. It has to look at much lower records.
Even better, after the first three rows are selected, created_at values are ordered. So filtering based on created_at also becomes easier.
Why this small change (switching two columns) made such as big difference in query execution?
Because of cardinality.
Which column has more unique values? created_at or user_id? Or in other words: do you have more users than timestamps? Probably not.
That’s it. The column order in a composite index should follow the columns’ cardinality.
Other
Using temporary in the Extra column means MySQL creates a temporary table to produce the results. It can mean an in-memory or an on-disk temp table.
Using filesort means MySQL is unable to use the index to sort the results. It needs to copy the data and sort it separately. This can happen in-memory or on the disk. You probably sort or group based on a column that is not part of an index.
They can slow down you queries. The problem is, there’s no universal solution and it depends heavily on your specific query. But usually you can:
Check and optimize your indices. If GROUP BY or ORDER BY is used, make sure the columns are included in the index.
Sometimes a subquery can be better then a JOIN to avoid temp tables
And that’s it. These are the most obvious performance problems, in my experience.
Building a database engine
This whole article comes from my new book - Building a database engine
It discusses topics like:
- Storage layer
- Insert/Update/Delete/Select
- Write Ahead Log (WAL) and fault tolerancy
- B-Tree indexes
- Hash-based full-text indexes
- Page-level caching with LRU
- ...and more
Check it out: