« back published by Martin Joo on July 23, 2024
Ride-sharing with Redis
The following article is a post from my brand new Substack newsletter - Computer Science Simplified. Join the publication and become a real software engineer who understands the principles of computer science, system design, architecture, and software engineering in general.
Developers often think about Redis as a simple cache engine but it’s much more than that. It’s a robust key-value database that can be used for a number of different things.
In this post, we’re going to replicate some of Uber’s features. Of course, in an oversimplified, kind of naive way, but it’s going to be a working demo. A complete system design and scaling are not our top priority today.
Here are the features:
-
A user requests a new ride
-
The app determines the closest available driver to the pickup location
-
It sends a notification to the driver
-
The driver accepts the ride
These are the most important and interesting features of Uber or any ride-sharing app. In order to build them, the app needs the following things:
-
Tracking the current location of drivers
-
Keeping track of the drivers’ current statuses (available, not available, etc)
-
Selecting the closest available driver(s) based on the pickup location
All of these are “temporary.” The current location of a driver changes from minute to minute. The current status also changes very frequently. The application writes and reads these very often. So we need to satisfy the following criteria:
-
Handling a high number of writes
-
Reads must be very fast
We don’t need to store the data for the long term. I mean, to develop these features. Of course, we can store them for statistics and reporting but that’s another feature and probably another database.
Redis checks all of those boxes. It has a pretty high throughput, and reading data is blazingly fast© We will use the following data structures:
-
Geometry
-
Set
-
Sorted set
High-level overview
Real Uber has more than one application. One for the drivers and another one for the passengers. In this example, we’ll be working on only one codebase.
Since Uber is a location-based service a real architecture would include multiple Redis instances in different regions. There’s no point in tracking ALL drivers’ locations in one Redis instance. You don’t want to have the current location of driver A who lives in Chicago and driver B located in Paris. These data should be stored in different instances in different regions. The rest of this post assumes we are designing and building the app and the database in one specific region.
This is the high-level overview of requesting and accepting a ride:
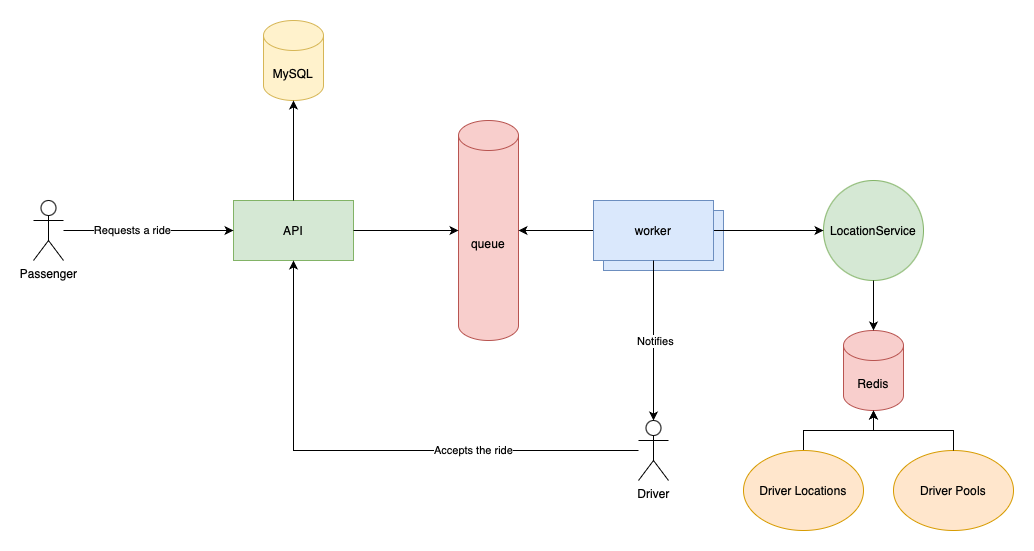
The main components are:
-
API handles the passenger’s and driver’s requests and coordinates the process
-
There’s a queue where the API dispatches jobs when the app needs to handle a new ride
-
Workers execute the jobs
-
They communicate with a
LocationService(which is only a class, not a separate microservice) that can locate the closest drivers to the passenger -
The
LocationServicerelies on Redis to get available drivers from the driver pools and run geometry queries using the drivers’ current locations -
And of course, there’s a MySQL database as well
Let’s start with geometry!
Geometry
Redis offers geospatial indices that can store longitude and latitude data and you can search, compare, and manipulate them very effectively.
We can add new coordinates using the GEOADD command:
GEOADD cities 19.0460277 47.5097778 Budapest
“cities” is the name of the key, 19 is the longitude, 47 is the latitude, and “Budapest” is the item. This example is a list of cities with coordinates and names.
To store these values, Redis under the hood creates a sorted set:
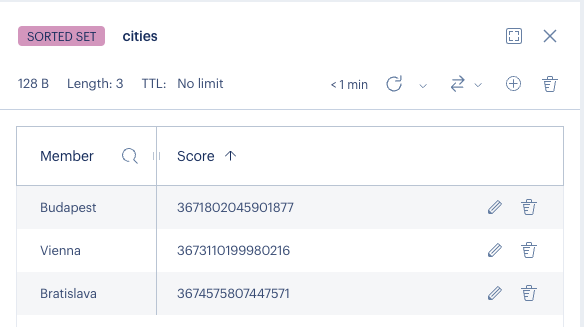
The GUI is called Redis Insights
It’s a sorted set with three members and three scores. A set is like an array or list but it’s unique. So you cannot add another “Budapest” to it. Each member has to be unique.
A sorted is a set but each member has a score and the whole set is sorted based on that. In this case, we don’t add scores manually. Redis calculates one from the longitude and latitude values. It uses a technique called Geohash where the coordinates are transformed into a 52-bit integer. From the Redis docs:
The way the sorted set is populated is using a technique called Geohash. Latitude and Longitude bits are interleaved to form a unique 52-bit integer. We know that a sorted set double score can represent a 52-bit integer without losing precision.
So we have a list of cities with coordinates (hash values to be precise). The GEODIST command can be used to calculate distances between them:
GEODIST cities Budapest Vienna
"212792.4038"
The distance between Budapest and Vienna is 21,2792 meters. It can return kilometers as well:
GEODIST cities Budapest Vienna km
"212.7924"
It’s 212 km which seems right (sorry USA guys🤷 Here are some other funny things for you: kilogram, centimeter, liter, TDI).
In an Uber-like app to find the closest driver to the user we don’t necessarily want to use GEODIST because it works with only two points. When a user requests a ride we rather want to get every driver in a given radius. For example, in a 5km circle where the central point is the user. This way we can quickly get all nearby drivers.
The GEOSEARCH command can be used such as this:
GEOSEARCH cities FROMLONLAT 18.428118 47.195154 BYRADIUS 100 km
1) "Budapest"
This command returns all cities located within a 100 km radius centered at the 18, 47 coordinates:
Budapest is located in this radius so the command returns it.
FROMLONLAT stands for “from longitude and latitude” and it accepts two values. The command also works with members, so we can also do this:
GEOSEARCH cities FROMMEMBER Budapest BYRADIUS 500 km
1) "Budapest"
2) "Vienna"
3) "Bratislava"
The FROMMEMBER option accepts a city name that becomes the central point in the search.
There are a few other options such as:
-
WITHDISTreturns not just the city names but the distances as well -
BYBOXsearches inside a rectangle instead of a circle -
ASCandDESCsets the order just like in MySQL
In this example, we’re going to use this command:
GEOSEARCH cities FROMLONLAT 18.428118 47.195154 BYRADIUS 100 km
Of course, instead of cities the app will search for drivers, the centric point will be the pickup location, and the radius becomes much smaller.
In the application, there’s an API endpoint to update a driver’s current location:
PATCH /api/drivers/{driver}/current-location
The API accepts 2 parameters, longitude and latitude. To update the location we can use the GEOADD command:
GEOADD drivers:current-locations 18.428118 47.195154 19
The last argument (19) is the driver ID.
Driver pools
In order to find the closest available driver when a user requests a ride we need to introduce statuses for the drivers. This is the bare minimum:
-
Available means that the driver can take a new passenger.
-
Not available means that the driver is currently transporting a passenger so he cannot pick up a new one.
-
On-hold means that the driver has already accepted a ride and he is commuting to the pickup location. But he’s currently not transporting a passenger.
I’ll call these “driver pools”.
When searching for a nearby driver we want to look for available ones. There are at least two different ways to implement these statuses.
Hash
A hash is a simple hashmap in Redis that looks like this:
key: driver:29
value:
{
"status": "available"
}
The key is driver:29 where 29 represents the driver’s ID. The value is a map that has fields. In this example, the only field is status. In this setup, every driver has a dedicated hash.
Adding a hash like this can be done with HSET:
HSET driver:29 status "available"
Pros:
-
Superfast.
HSEThas a time complexity of O(1). It’s constant time meaning it doesn’t matter if you have 10 or 10,000,000 hashes it always takes a constant time. -
Easy to use. If you want to query the status of driver 29 you just do
HGET driver:29 statuswhich is also O(1) so reading is super fast as well.
Cons:
- Since each driver has a dedicated hash it’s hard to search for available drivers. We cannot treat them as one list or array. Instead of using an array, we should gather all driver IDs from the database and then check every key in Redis if the given driver is available or not. It would look something like this:
$availableDrivers = [];
$drivers = Driver::all();
foreach ($drivers as $driver) {
$result = Redis::hget('driver:' . $driver->id, 'status');
if ($result === 'available') {
$availableDrivers[] = $driver;
}
}
- There’s one DB query and N Redis commands. Even though,
HGETis pretty fast we potentially run it millions of times which is pretty bad, of course. Also, querying all the drivers is pretty inefficient. This query returns drivers from New York when the user requests a ride in Madrid. If you want to fix that problem you need to execute geo search commands in MySQL to return only nearby drivers. But the whole point is that we want to use Redis because it’s much faster.
So using a hash is inefficient and kind of “annoying”. Having a list with all available drivers at any given moment is a much better solution.
Set
A list would be great for storing available drivers, but we know that each member must be unique so a set is more suitable. It’s a list with unique members, exactly what we need.
The SADD command can be used to add a new member:
SADD drivers:available 29
Using : in key names is a common practice in Redis. This set contains all available drivers at any given moment.
The SMEMBERS command returns every member:
SMEMBERS drivers:available
If the set is huge and it’s not possible the load every member into memory, the SSCAN command can be used to iterate over the set and load only a chunk of it at once into memory:
SSCAN drivers:available 0
The second argument (0) is the cursor that determines the start position. The command returns the new cursor and the members. Then the cursor can be used in the next call:
SSCAN drivers:available 0
"17"
1) "29"
2) "34"
3) "78"
...
SSCAN drivers:available 17
"32"
1) "129"
2) "134"
3) "156"
...
SSCAN drivers:available 32
"0"
1) "211"
2) "246"
When it returns 0 as the new cursor there are no additional elements.
The set looks like this:
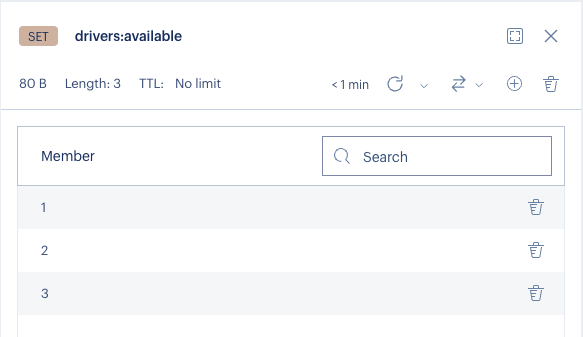
As of now, there are integer IDs in the set, but in a production app UUIDs or ULIDs would be a better choice.
Sorted set
When a driver is not currently available because he’s transporting a passenger we want to know when he’s going to be available again. For this, we can store a timestamp that is the estimated time of arrival or ETA for short. There are situations where there are no available drivers for a passenger. In this case, we might want to notify not available drivers. Specifically, not available drivers with the closest ETA date. If driver A drops off his passenger in 6 minutes but driver B will be transporting for another 20 minutes we want to notify driver A instead of B. Given that they are both close to the new passenger.
A sorted set is perfect for this use case. It’s a set but each member has a score and the whole set is sorted based on these scores.
This is what it looks like:
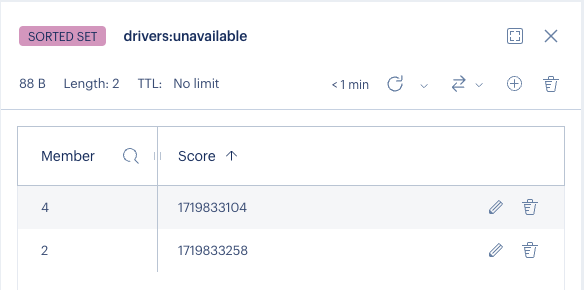
There are two unavailable drivers each of them has a timestamp as the score which is the estimated time of their arrival. As you can see, the set is sorted based on the scores. The driver who will be available earliest is at the front.
The ZRANGEBYSCORE command can be used to get the drivers with the earliest ETA. It’s an ugly name for a command, but it actually makes sense:
-
Z stands for sorted set. Each Redis command starts with a letter that describes the data structure. Since S is taken for sets, commands for sorted sets start with Z.
-
RANGE stands for, well range. It’s a range query that returns multiple members.
-
BYSCORE stands for, well by score. We can query members based on their scores.
-
Another variation of the command is
ZREVRANGEBYSCOREwhich is the same but it returns members in reversed order (REV).
This is how the command can be used to query drivers that are going to be available in a given time period:
ZRANGEBYSCORE drivers:unavailable 1719830104 1719833110
1) "4"
Another driver pool is on-hold drivers. A driver is on hold if he has already accepted a ride and he is commuting to the pickup location. But he’s currently not transporting a passenger.
This can be implemented using the exact same techniques. Another sorted set with a different key: drivers:on-hold. Except for the name, everything is the same. Adding members to a sorted set can be done with the ZADD command:
ZADD drivers:on-hold 1719830104 4
The first argument is the key, the second one is the score, and the last one is the actual value (driver ID in this case).
Finding the closest drivers
Now that we have locations in geospatial indices and different driver pools implemented with sets and sorted sets it’s time to locate the closest driver for a new passenger.
Read the entire article on Computer Science Simplified.
