« back published by Martin Joo on August 17, 2022
Microservices with Laravel - Communicating Between Services
In the first part we’ve talked about what’s the problem with monoliths and how do microservices solve these problems. In this part we’re going to discuss how to store data and communicate between services.Storing data in different services
The first big challenge that comes with microservices is storing data. This is harder than you think. The single most important thing is that you don’t want to have only one database. So we won’t do this:
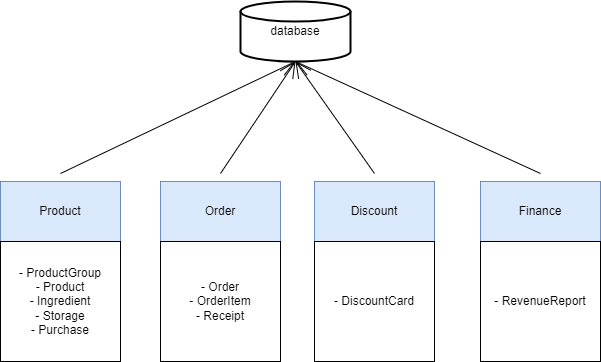
There are several problems here:
- Tight coupling. In this example, the Finance service needs to know every column and every detail about how a Product is stored in the DB. Finance is just a user of the product service, so it does not need to know if the ID is a string or an integer and so on.
- Low cohesion. Finance service will possibly break every time when someone changes the scheme of the products table. You make a change in the Product services and suddenly Finance stops working. This is bad.
- Shared responsibility is bad. Who’s in charge of modifying the scheme? You can say it’s easy, the scheme of products table is in the Product service, the scheme of orders table is in the Order service, and so on. It’s easy to keep track when you have 4 services. But what if you have 132 services? In one database basically, there are no boundaries, no rules about how the data is related to services, and who is responsible to manage this data.
- Too much dependency. We want each service to run independently from other services. If we have a giant, shared database it’s hard to achieve.
- And a bonus point: maybe we want a different type of database for a service, because it works better with NoSQL for example, meanwhile the rest of our services work better with SQL.
So here’s what we want to do instead:
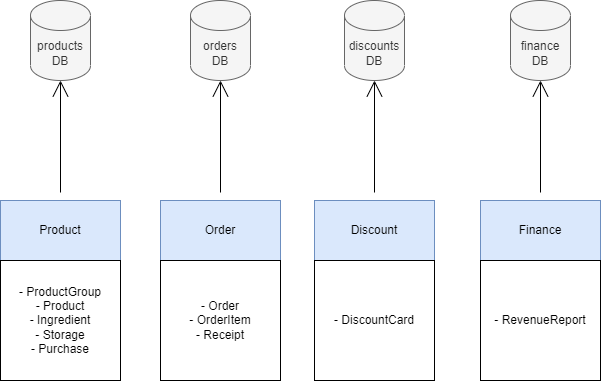
So every service has its own database (if it needs one). There are several benefits:
- Loose coupling. Much less coupling between services. Now Finance service does not depend on the scheme of products table. It only uses the shared models of the Product service.
- High cohesion. Now Finance service has no idea of the products table or products scheme. You can do whatever you want in the Product service and products DB, it will not break Finance.
- Well-defined responsibility. Now the Product service is in charge of the products DB. And no one else can touch it. Similarly, the Discount service is responsible for the discounts database and so on.
- No dependencies. Now every service runs independently from each other’s data. They are just using the shared models and communicating with well-defined contracts (APIs and events).
- Now Finance can use MongoDB, while Product has a MySQL db, but Order has PostgreSQL. There are no technical limitations.
Communication between services
The other big challenge we have to solve is communication between services. So we split our application into different, small services. But we are no longer able to call functions between two services like we were in a monolith. In other words, how does the Finance service get the orders for a report? There are two ways to solve that problem (in fact there are more than two solutions, but we will focus on these two).
Sync communication
This is the easiest to understand and implement so we’ll start here. We are using a request-response model to communicate between services. We are not talking about HTTP exclusively, but this is the most common one (other solutions can be RPC and protocol buffers).
Let me show you a diagram first:

Each arrow represents an HTTP API request. So whenever a service needs some data from another service it sends a request and gets back a response with the data. It’s called sync communication because everything happens in order:
- The browser sends an HTTP request to the Finance service and waits for a response
- The finance service sends a request to the Order service and waits for a response
- The finance service sends a request to Product service and waits for a response
- Both Order and Product service sends a request to Discount service
After every request is served, the Finance service does its calculations and responds to the user’s request.
It has some advantages:
- Easy to understand. It’s very similar to function calls in a monolith, except they are HTTP requests. But the flow of information is kind of the same.
- You can implement some services without a database. In the restaurant domain, the Finance service can be a good example. It does not necessarily require a database, because all the data that it needs is already there in some other services. So it’s a possible solution to just request this data.
Besides, it is easy to understand and implement, but it has some major drawbacks:
- Dependency between services. This is an important one. We want to use microservices because we can develop services independently from each other, and we can deploy them whenever we want. If we couple them with HTTP calls it just makes life harder.
- More sources of errors. We make a lot of HTTP requests inside our services. What happens if the Order -> Discount request fails? Then the whole request chain fails. What happens if a service is down, and a timeout occurs? Then the whole request chain is failing. This is gonna take us to our next drawback.
- Latency. We make lots of requests. Imagine we have just 30 services. We can easily make a request chain of 20-30 HTTP calls. It’s just slow, way slower, than 20-30 function calls in a monolith.
- Circular dependencies. What happens if the Order service calls the Product service, then the Product service calls the Discount service, but for some reason, the Discount service also calls the Product service?

If you have a lot of services, and multiple teams working on them, it is very easy to do something like this. And now you have a circular dependency, and an out-of-memory or max execution time exceeded error message. These HTTP calls are very similar to function calls in a big monolith, where every module calls every other module.
Disclosure: Don’t get me wrong, sync communication via HTTP is not evil by nature! You’ll see later in this book, that we use this technique because it’s simple and easy to use. In fact, sometimes you don’t have another choice. Sometimes you just have to make an HTTP call, because it’s synchronous, and you need an immediate response. But in my opinion, it’s not a good solution, to build an entire system around it.
So what other alternative do we have?
Event-driven communication
In this communication style, we have to introduce a new component, called the event bus. We will talk about it in more detail later, and we will implement it, but for now, think about it as a broker who delivers messages between services.
In this model, we also rely on the concept that each service has its own database.
Let me show you an example:
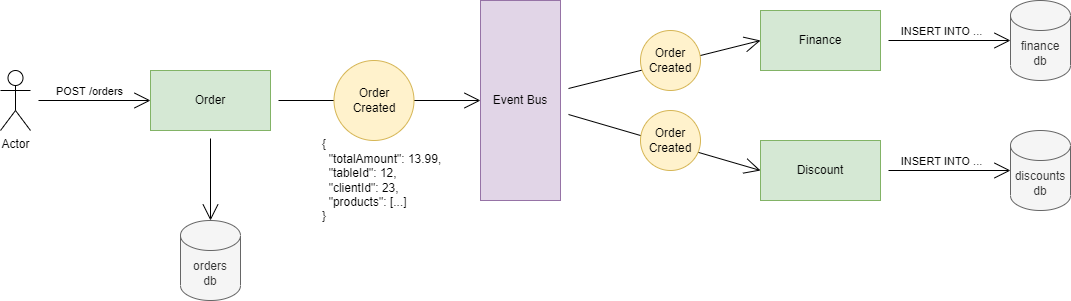
Let’s review what is happening here:
- The user creates a new order
- Order service gets an HTTP POST request with the order data
- It does its job, calculates some stuff, and writes it into DB. So now the new order is created
- The Order service then publishes an event called OrderCreated to the Event Bus*.* It contains all of the important information about the order, like the total amount, which table, who the client is, the products array, and so on.
- The Event Bus pushes the OrderCreated event to all the services that are interested in it. For example, the Finance service needs the newly created order to calculate the daily revenue. But maybe the Product service does not care about orders, so there is no need to push. (By the way, technically it can be a pull model also, where services pull the new events out of the event bus)
- The finance service gets the OrderCreated event, processes it, and makes an insert or an update on its own database.
So this is how every service builds its own database. By communicating through an event bus, and consuming interesting events. In this way, every service has every important data that it needs. No need to make an HTTP request from Finance to Order anymore. Because as the events come into the Event Bus, every service processes it and saves the important data.
One more important note:
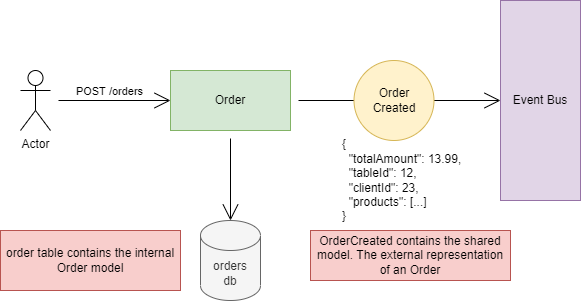
When the Order API processes the POST request and saves an Order instance into the orders table, this is what we call the internal Order model. It’s only visible to the Order service, and it may contain 20 columns.
When the Order service publishes the OrderCreated event, it contains the shared Order model. It’s visible to the whole system and may contain only 5-10 columns. Events and the Event Bus always contain language-independent formats, like JSON, so they can be processed by any language.
The important takeaway here is that only the shared, external model (DTO) can leave the service boundaries.
The promise of microservices
I hope all of this sounds good and architect-y, but there is one more important question. Why are we doing this?
So, here are some of the advantages of microservices:
- There is no huge codebase anymore. All of our services will be small, easy to reason about, and simple. This is a huge gain if you think about it.
- It’s more resilient and reliable. Almost every error and bug has a scope of one service. So if something goes wrong in the Finance service, everything else will work properly. This is also a huge advantage. Basically, it’s way harder to make a mistake that brings the whole application down.
- You can deploy small changes frequently. Because we have small services, it’s very easy to deploy and ship new features. If you identify the right service boundaries, you can make new features and changes that only affect one or two services.
- Availability. You can use Docker Swarm or Kubernetes to orchestrate your services. This means that you can run mission-critical services in more instances, you can easily isolate worker processes, and you can auto-scale more effectively.
- You can use 4-5 member teams to develop and maintain two or three services. It’s much easier to scale your organization.
- It’s also easier to create autonomous and cross-functional teams. This means that every team can handle the whole lifecycle of a feature or a service, which includes:
- Idea
- Design
- Development
- QA
- Deployment
- Shipping to production
- Maintenance
- The above point is possible because they only need to know a couple of services from bottom to top. It contains a few thousand lines of code. Not millions.
- You can use multiple languages, multiple frameworks, or technologies in your services. You can use Laravel in the Product service, but use Symfony in the Finance service. They are communicating via API calls and events, not function calls, so it doesn’t matter what’s inside a service. You can also write some Nodejs or Python services if you want. You can use MongoDB for a specific service. And so on.
- Fast and small pipelines. Each service is about a few hundred or thousand lines of code, so tests will be run fast, images will be built fast, and so on. There are no more 20, 30 minutes long pipelines.
But of course, microservices are no silver bullet, so there are also some drawbacks:
- Harder to understand. There are a lot of services communicating with each other. There are a lot of containers running, and multiple databases to migrate and maintain.
- Harder to debug. Let’s say a user clicks a button, and the operation goes through 5 services. Now if something bad happens, you may have to debug 5 different Laravel projects. If you use event-driven communication it gets even worse, because it’s asynchronous, so it’s even harder to debug.
- Harder to monitor. You could have 30 services, and 75 running containers to monitor. You have to learn specific, and sometimes complicated tools to monitor your running application (like Prometheus).
- Harder to collect logs. Again, you have 75 running containers which dump logs to stdout. It gets even worse if you have more than one server (and you probably have more). Once again, you need to learn specific tools to see your logs (like ELK or EFK stack).
- You could run into problems that only come with distributed systems. For example, a service publishes a couple of events, and somehow it’s processed in the wrong order, and now you have some data inconsistency in your databases. You have to debug multiple services, events, databases, and so on.
- Sometimes you have to make a change in every service. Let’s say you have 14 services, and you found a great Laravel package, maybe some static code analysis package. You want to use it. But you want to use it in every service. So you have to install it in all 14 services. If you need this to run in your pipeline, you have to make changes to 14 pipelines.
As you can see there are some serious issues that come with microservices. Problems that you never have in a monolithic application. And you need to learn some new stuff to effectively operate this architecture.
But one thing is for sure: if you do it right, and you do it with the right application, it is worth it.
Next Steps
As you may know, I published a book called "Microservices with Laravel." Check it out if you want to learn more!
