« back published by Martin Joo on July 17, 2024
LRU caches
The following article is a post from my brand new Substack newsletter - Computer Science Simplified. Join the publication and become a real software engineer who understands the principles of computer science, system design, architecture, and software engineering in general.
Introduction
LRU cache stands for Least Recently Used cache. It’s a technique that assumes that the most recently used data is likely to be used again in the future. Therefore, it caches a fixed number of elements and evicts the least recently used ones.
Take a look at the “Recent Searches” page on Spotify:
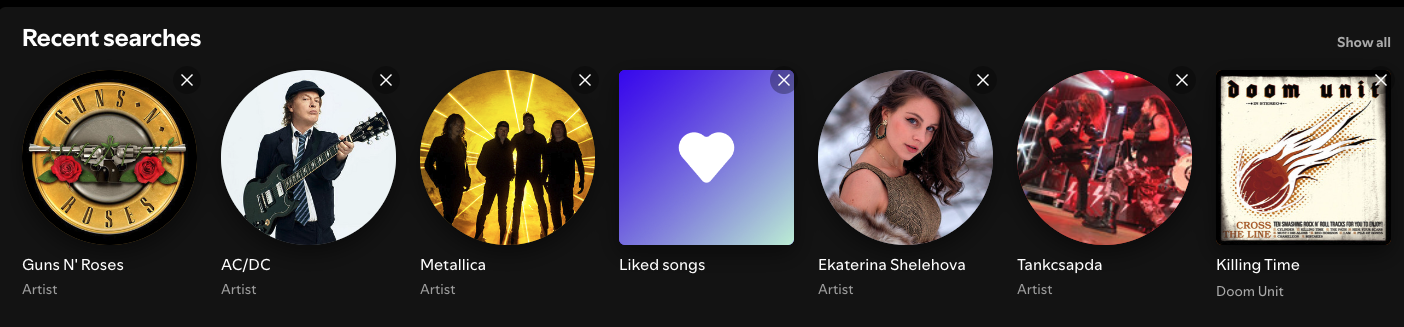
I wonder how Metallica is only the 3rd
The first item was accessed more recently than the last one. If I search for something new, the last item will be removed and the new one is pushed at the beginning.
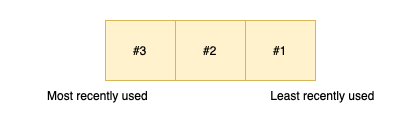
Let’s say we have an LRU cache with a capacity of 3. If a user reads the following items in the following order:
-
#1
-
#2
-
#3
The LRU cache looks like this:
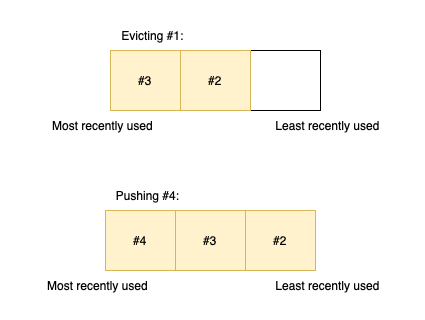
If the user accesses #4 then #1 gets evicted (since the capacity is only 3) and #4 gets pushed at the beginning (as the most recently used item):
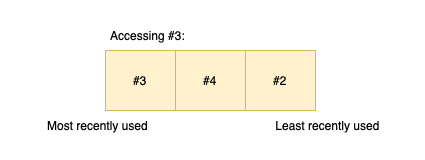
When an existing element is accessed it has to be pushed at the beginning of the cache:
Since it’s a caching technique it must be very fast and efficient. There are numerous ways of implementing an LRU cache. We’re going to build 4 different ones using:
-
Arrays
-
Linked lists
-
Redis lists
-
Redis sorted sets
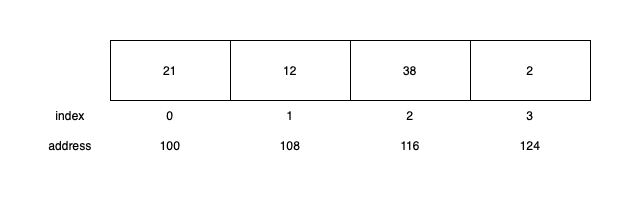
Each of them will use an additional hashmap. It is needed because accessing an item should be very fast. Just imagine an array with 10,000 elements and the user wants to access the one with ID f4a7b2ff-1b2a-4986-a54d-31abc06fac00. You need to walk the whole array to find the right element. Using a hashmap makes reading a constant time operation.
I’m going to benchmark the different versions.
LRU cache with arrays
Each of the LRU implementations extends this base class:
namespace App\Cache;
abstract class LRUCache
{
public function __construct(protected int $capacity)
{
}
abstract public function put(string $key, mixed $value): void;
abstract public function get(string $key): mixed;
}
Putting a new item into the cache is easy:
If the current length is less than the capacity the item can be prepended at the beginning of the array.
If the current length exceeds the capacity the last element needs to be removed from the array and the new one can be prepended.
class LRUCacheArray extends LRUCache
{
/** @var array <string, mixed> */
private array $map = [];
private array $items = [];
public function put(string $key, mixed $value): void
{
if (count($this->items) >= $this->capacity) {
$removedKey = array_pop($this->items);
unset($this->map[$removedKey]);
}
array_unshift($this->items, $key);
$this->map[$key] = $value;
}
}
There are two properties:
-
$mapis a simple hashmap that stores the actual key-value pairs. This is the actual cache. -
$itemsis the array that contains keys in the right order.
If the current length of the array exceeds the capacity it removes the last item from the array and from the map. Then it pushes the new element at the beginning (with array_unshift) and sets the key-value pair in the map.
Getting an element is a bit more complex since we have to update the order as well:
public function get(string $key): mixed
{
if (!isset($this->map[$key])) {
return null;
}
$this->update($key);
return $this->map[$key];
}
If the item is not found it returns null otherwise it returns the value using the map. Now you can see why we need a hashmap. Returning the value based on the key is an O(1) operation. It’s constant time. No matter if the map has 10 or 10,000 elements. Iterating through an array is an O(N) operation. It does matter if the array contains 10 or 10,000 elements. Since this array is not sorted, binary search cannot be used (which would be O(log(N)).
The update method moves the accessed element to the front of the array:
private function update(string $key): void
{
$idx = array_search($key, $this->items);
if ($idx === false) {
return;
}
unset($this->items[$idx]);
$this->items = array_values($this->items);
array_unshift($this->items, $key);
}
array_search finds the index of $key. unset deletes it from the array, then array_values resets the indices so it doesn’t have “gaps.” Finally, array_unshift prepends the key to the beginning of the array.
That’s it! We have a working in-memory LRU cache using arrays. I wrote the following (which I’ll use to test the other implementations as well):
namespace Tests\Unit;
class LRUCacheArrayTest extends TestCase
{
#[Test]
public function it_should_keep_elements_in_the_right_order()
{
$lru = new LRUCacheArray(2);
$lru->put('first', 1);
$lru->put('second', 2);
$this->assertSame(1, $lru->get('first'));
$lru->put('third', 3);
$this->assertNull($lru->get('second'));
$lru->put('fourth', 4);
$this->assertNull($lru->get('first'));
$this->assertSame(3, $lru->get('third'));
$this->assertSame(4, $lru->get('fourth'));
}
}
As I said, an LRU cache should be pretty efficient so let’s see how it performs.
Performance
First, let’s estimate the time complexity:
-
count() is O(1) since each array stores its length.
-
array_pop() is also O(1) since we know the length of the array and an element can be accessed randomly.
-
array_unshift() is O(N). It has to reindex all the keys.
-
array_search() is also O(N). Since the array is not sorted in the worst case, it has to search through the entire array, resulting in a linear time complexity.
-
array_values() is also O(N). This function creates a new array with the same elements, which takes linear time proportional to the size of the input array.
As you can see, an array-backed LRU O(N) functions. That makes both put() and get() an O(N) operation. In other words: slow. O(1) is the goal.
But how slow is it?
I created the following benchmark:
class Benchmark
{
public function run()
{
$benchmark = function (LRUCache $cache, int $n) {
foreach (range(1, $n) as $i) {
$cache->put($i, $i);
}
foreach (range(1, $n) as $i) {
$cache->get($i);
}
};
\Illuminate\Support\Benchmark::dd([
'array:1_000' => fn () => $benchmark(
new LRUCacheArray(1_000), 1_000
),
'array:10_000' => fn () => $benchmark(
new LRUCacheArray(10_000), 10_000
),
'array:20_000' => fn () => $benchmark(
new LRUCacheArray(20_000), 20_000
),
'array:100_000' => fn () => $benchmark(
new LRUCacheArray(100_000), 100_000
),
]);
}
}
It sets and reads N number of items, where N is:
- 1,000
- 10,000
- 20,000
- 100,000
Here are the results on my MacBook M2 Air:
- 1,000 items → 48.240ms
- 10,000 items → 2,410.047ms → 2.4s
- 20,000 items → 9,884.078ms → 9.8s
- 100,000 items → 275,203.395ms → 275s → 4.5 minutes
Even though, I think the algorithm itself is O(N) the results are much, much worse than that.
The difference in runtime between 1,000 and 10,000 items is not 10x but 50x. The difference between 10,000 and 100,000 is not 10x but 114x.
I don’t know the exact reasons for it. My guess is that the increasing memory usage (allocating 100k items vs 10k) causes a big increase in runtime as well. This shows you the slowness of O(N) or O(N^2) algorithms. The more items you have the worse it gets.
Now imagine if the “Suggested from your activity” section on Dropbox would take 2.4s for every 10,000 items.
This whole article comes from my new Substack newsletter - Computer Science Simplified
Check it out:

LRU cache with linked lists
Unlike an array, a linked list is not a contiguous data structure that can be addressed with indices. It contains nodes that live in memory in perfectly random places. The connection between the nodes is maintained with pointers.
This is a linked list:
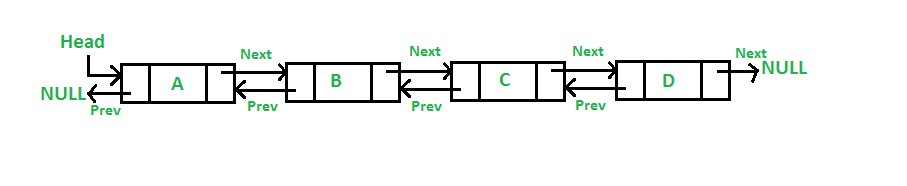 Source geeksforgeeks.org
Source geeksforgeeks.org
To be precise, this is a double-linked list. Each node has a previous and a next pointer. The previous points to the previous node and the next to the next one as shown in the image.
The first element is the head and the last one is the tail. The prev pointer of the head points to null and the next pointer of the tail also points to null. These null pointers designate the beginning and the end of the list.
Each node is an instance of the Node class:
namespace App\Cache;
class Node
{
public ?Node $prev = null;
public ?Node $next = null;
public function __construct(
public string $key,
public mixed $value,
) {}
}
It has the two pointers and the necessary data which in this case, is a key and a value.
The properties and the constructor of the LRUCacheLinkedList class look like this:
namespace App\Cache;
class LRUCacheLinkedList extends LRUCache
{
private Node $head;
private Node $tail;
/** @var array<string, Node> */
private array $map = [];
private int $length;
public function __construct(int $capacity)
{
parent::__construct($capacity);
$this->length = 0;
$this->head = new Node('', null);
$this->tail = new Node('', null);
$this->head->next = $this->tail;
$this->head->prev = null;
$this->tail->next = null;
$this->tail->prev = $this->head;
}
}
It has a head and tail property that will point to the first and the last node. Since a linked list doesn’t know its length and there’s no count() function we need a $length property as well to keep track of the list’s length.
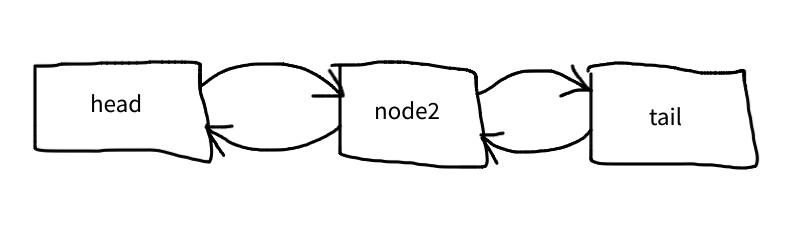
The head of an empty list points to the tail and vice versa:

To put an item into the list we need to do the following logic as before but dealing with linked list nodes instead of arrays:
public function put(string $key, mixed $value): void
{
if ($this->length >= $this->capacity) {
$this->removeLeastRecentlyUsed();
}
$node = new Node($key, $value);
$this->append($node);
$this->length++;
}
Once again, if the capacity is exceeded the least recently used item is removed from the list. Later, we’re going to see what happens inside the removeLeastRecentlyUsed() method.
Otherwise, a new Node is created, is appended to the end of the list, and the length is increased. Yes, in this case, the order is reversed compared to arrays. The most recently used nodes are located at the end of the list and the least recently used ones are at the beginning. You can do it the other way around, but I found it more easy to understand this way.
Appending a node to the end of the list looks like this:
private function append(Node $node): void
{
$node->next = $this->tail;
$node->prev = $this->tail->prev;
$node->prev->next = $node;
$this->tail->prev = $node;
$this->map[$node->key] = $node;
}
If you’re not usually working with linked lists this is very hard to understand.
Let me guide you through it with amazing drawings.
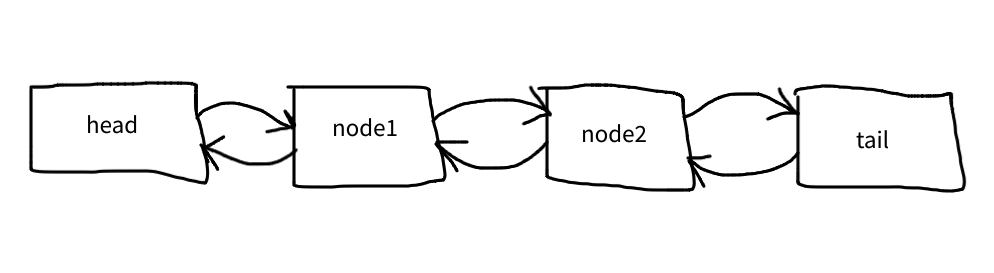
Given we have the following list with two nodes and we need to append a third one:
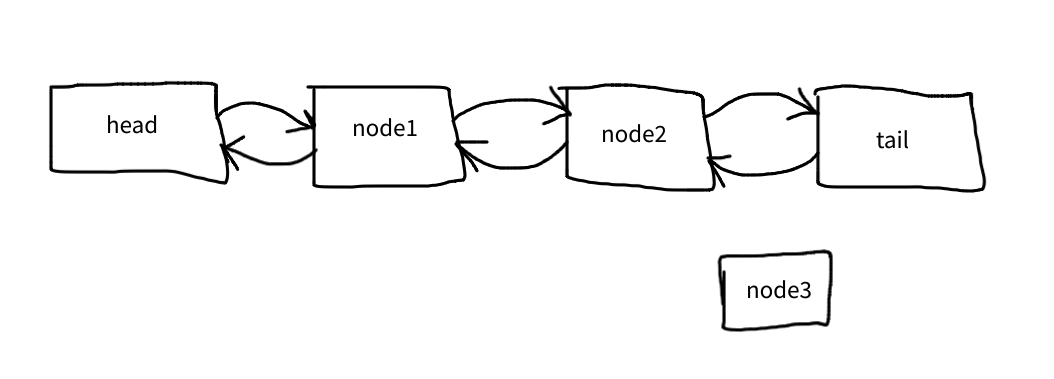
The first line connects node3 to the tail:
$node->next = $this->tail;
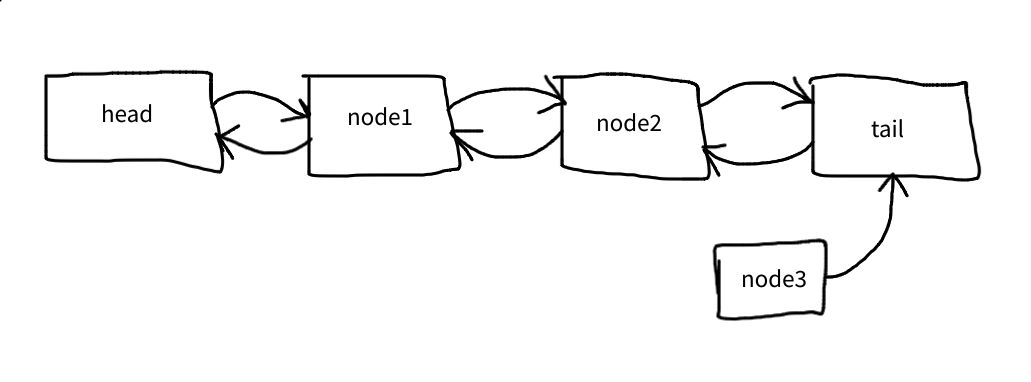
The seconds one connects node3 to node2:
$node->prev = $this->tail->prev;
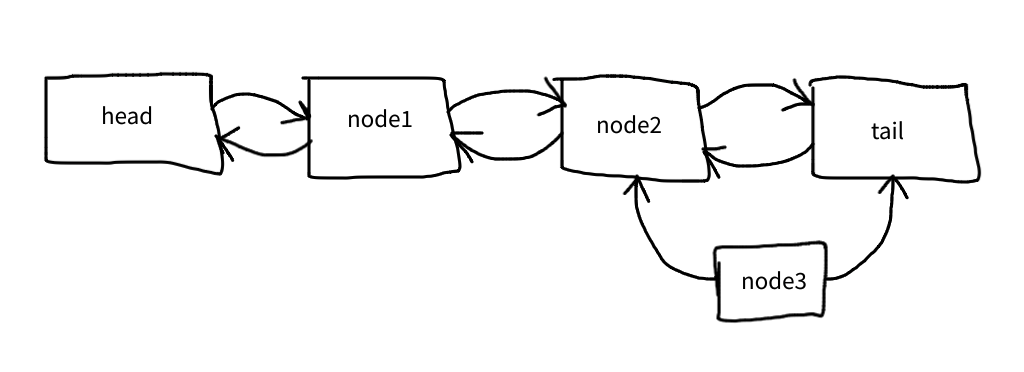
This is where it gets mind-boggling:
$node->prev->next = $node;
But what it really means is this: node2’s next pointer becomes node3:
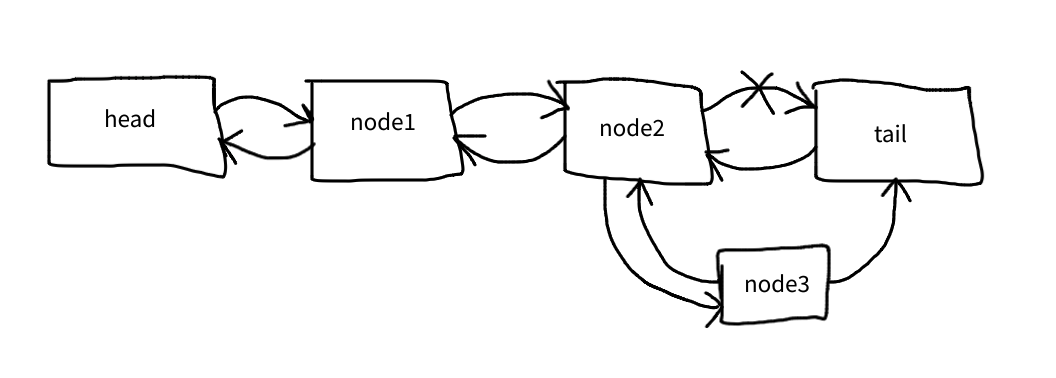
Now the only missing link is the tail’s previous pointer to node3:
$this->tail->prev = $node;
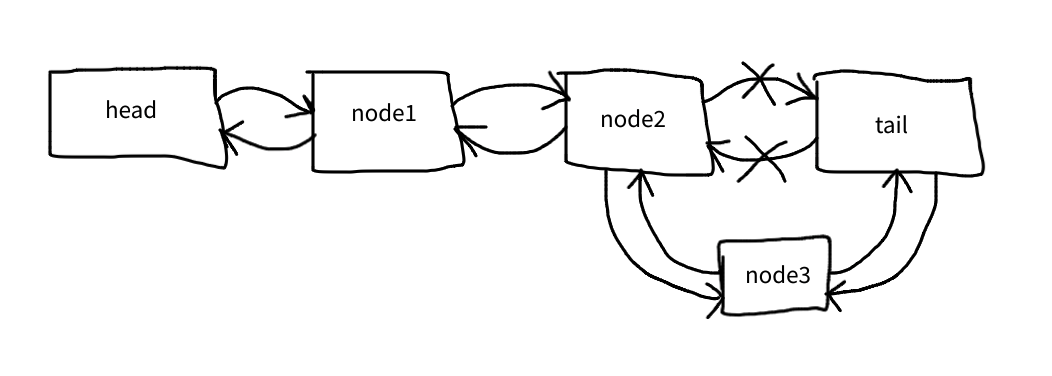
In other words, we added two new arrows with these lines:
$node->next = $this->tail;
$node->prev = $this->tail->prev;
And then changed the existing arrows with these two lines:
$node->prev->next = $node;
$this->tail->prev = $node;
Do you like this post so far? If yes, please share it with your friends. It would be a huge help for the newsletter! Thanks.
Appending the new node at the end of the list is only half the job. The other half is removing the least recently used elements if the capacity is exceeded:
private function removeLeastRecentlyUsed(): void
{
$node = $this->head->next;
$this->head->next = $node->next;
$node->next->prev = $node->prev;
$this->length--;
unset($this->map[$node->key]);
}
Given the same list as above, let’s remove node1:
The very first line just sets a variable to node1 in order to simplify things:
$node = $this->head->next;
The second line connects the head with node2:
$this->head->next = $node->next;
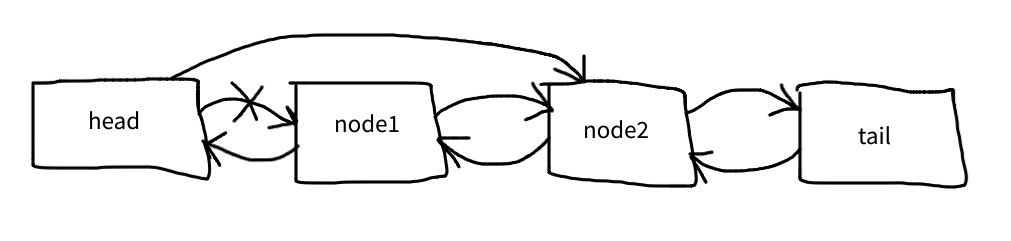
And the third line connects node2 to the head:
$node->next->prev = $node->prev;
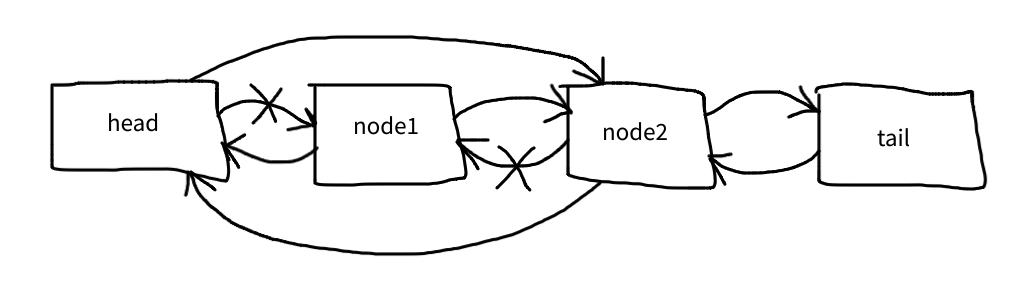
And now the list looks like this:
We don’t need to clear out node1’s prev and next pointers. The head is not connected to it anymore. In fact, no other node is connected to node1 anymore. As I said earlier, a linked list is not a “container” such as an array. If you want to iterate through it you just need the head:
public function iterate(Node $head)
{
$node = $head;
while ($node->next) {
// ...
$node = $node->next;
}
}
While there’s a next pointer the loop can continue. Since no element points to the deleted node, it won’t be a problem.
So we can put a new node into the cache by appending it to the end of the list and removing the least recently used node if needed:
public function put(string $key, mixed $value): void
{
if ($this->length >= $this->capacity) {
$this->removeLeastRecentlyUsed();
}
$node = new Node($key, $value);
$this->append($node);
$this->length++;
}
Getting an element is a little bit simpler:
public function get(string $key): mixed
{
if (!isset($this->map[$key])) {
return null;
}
$node = $this->map[$key];
$this->detach($node);
$this->append($node);
return $this->map[$key]->value;
}
Since recently used elements are located at the end of the list we need to detach and append the currently accessed node to the end. We’ve already discussed append.
Detaching a node couldn’t be simpler:
private function detach(Node $node): void
{
$node->prev->next = $node->next;
$node->next->prev = $node->prev;
}
This is the equivalent of unset($this→items[$idx])
It can be imagined such as this:
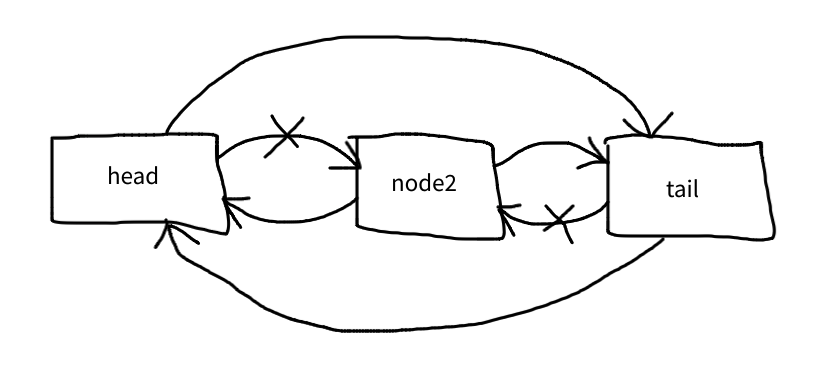
node2 is not part of the list anymore.
And that’s it! We have a working LRU cache implemented with linked lists.
Of course, instead of implementing your own linked list, you can always use SplDoublyLinkedList from PHP’s standard lib.
Substack
This whole article comes from my new Substack newsletter - Computer Science Simplified
There's a part II that is only available on Substack.