« back published by Martin Joo on August 6, 2025
Materialized views
On the 9th of September I'll launch a new book, System Design with Laravel
Lots of applications have some kind of report or dashboard feature. Often comes a point when these slow down. If you have millions of records and a complicated query that serves a larger report, your query can run for seconds. Or you know, 10+ seconds in a proper legacy system.
If you have 50 users who run the 3s report simultaneously, your system is down.
The best solution to these problems is probably setting up a specialized database (like ClickHouse or Redis) that serves the reports and dashboard.
However, in a lot of cases, it's not a viable option:
- The project is not important enough
- You have other deadlines
- You don't want to bring a new technology into the tech stack
- Sometimes it's just too much work and you have other priorities (in legacy systems, for example)
Fortunately, there's an easier solution. We can add special tables to a MySQL (or Postgres, or SQLite) database that serves one specific report pretty fast.
There are three kinds of tables in most relational databases:
- Standard
- View
- Materialized view
A view table is a way to "store" frequently executed queries:
create view active_users as
select id, name, email
from users
where is_active = 1
You can use this as a regular table:
select *
from active_users
The view table is not stored on the disk. It's just an alias to a query. The real query is always executed.
A materialized view is similar to this, but it's actually stored on the disk. Meaning, you can create a materialized view table for a complex dashboard query, and you can get the data without running a complex query again and again.
My main database is MySQL. It doesn't support materialized views, but we have a workaround.
Let's say the app needs a dashboard that shows the amount spent and the total number of orders by customers. Something like this:
| customer_id | order_count | total_spent |
|---|---|---|
| 1 | 19 | 2358 |
| 2 | 72 | 11784 |
We can easily create a table with this exact data:
create table customer_order_summary as
select customer_id, count(*) as order_count, sum(total) as total_spent
from orders
group by customer_id;
This creates a customer_order_summary table using the query.
If you need the data on the dashboard you run a simple query:
select *
from customer_order_summary
This query will run orders of magnitude faster than the original one.
The only problem is that the "materialized view table" won't update automatically. We need to refresh it manually using one of the following strategies:
- Scheduled. In the background, we run scheduled jobs that truncate the table and insert the new data:
truncate customer_order_summary
insert into customer_order_summary
select ...
Updating the table periodically is easy. The trade-off is that you won't have real-time data. There's always gonna be a delay.
- On insert/update. Instead of periodic background jobs, we can insert/update new data into the materialized view on the fly when something changes. It's going to be near real-time, but it requires more attention. It's easy to forget about not-so-trivial use cases, and you'll end up with data inconsistency.
You can use this technique to serve simple and a bit more advanced reports. The best use cases would be daily/monthly/yearly sales by customers.
You can use this technique to serve simple and a bit more advanced reports. The best use cases would be daily/monthly/yearly sales by customers.
Now, let's see the performance implications in an order management system.
I seeded ~700k orders:
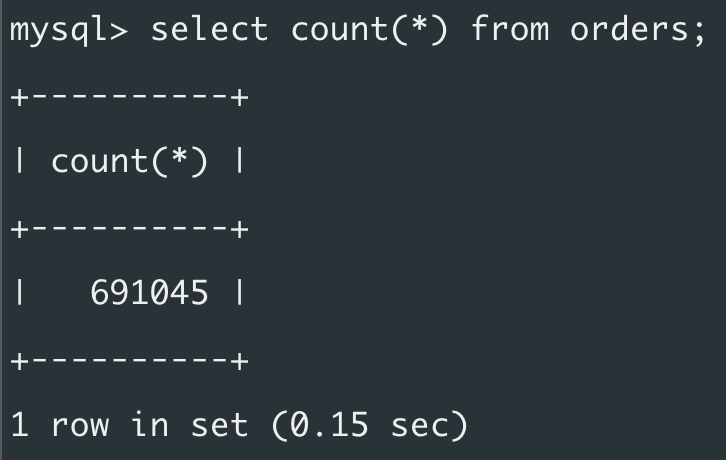
And ~7M order items:
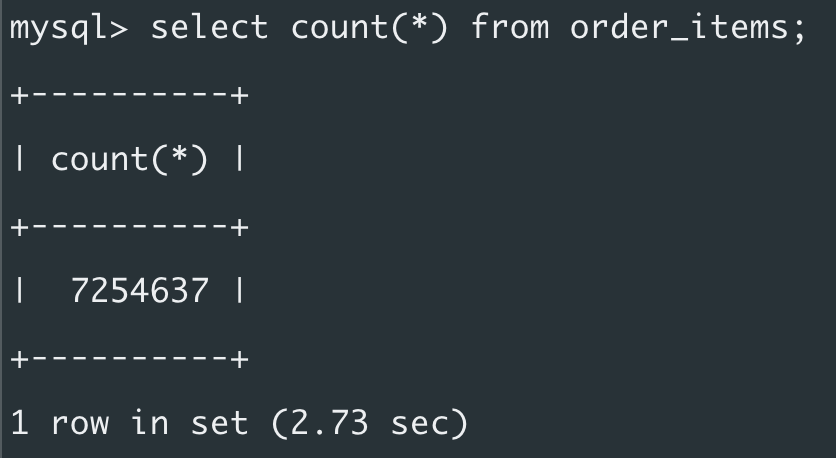
The monthly sales report only cares about orders. ű
And there are only ~700k of them.
Without the view table, the average response time is already 0.5s:

Using the materialized view, the average response time is 0.01s:

The difference is obvious:
- Using the orders table, MySQL needs to process ~700k records
- Using the view table, it processes only 1 record
In this example, I only have data for May 2025, so the view table has only one record. This single record represents ~700k orders.
And this is where the magic happens.
I'd like to quote Hussein Nassar:
The secret of processing large amounts of data is to avoid processing large amounts of data.
Let's think about how much this view table reduces the number of records MySQL needs to process.

It's a 1:3,000,000 ratio. For every 3,000,000 orders, we have one record in the view table, on average.
The view table scales with the number of months.
Not with the number of orders. And this is a huge win.
In my experience, we start having performance issues after a few million records in MySQL. Let's call it 2M. Until the view table doesn't contain 2M records, we are good. 2M records translates to 2M months. It is 166,666 years. It could be better, of course, but it's good enough.
This entire article comes from my new book System Design with Laravel
