« back published by Martin Joo on May 14, 2023
DevOps With Laravel: Queues and Workers in Production
This article contains some useful tips on how to run queues and workers in production.
supervisor
The most important thing is that worker processes need to run all the time even if something goes wrong. Otherwise they'd be unreliable. For this reason we cannot just run php artisan queue:work on a production server as we do on a local machine. We need a program that supervises the worker process, restarts it if it fails, and potentially scales the number of processes.
The program we'll use is called supervisor. It's a process manager that runs in the background (daemon) and manages other processes such as queue:work.
First, let's review the configuration:
[program:worker]
command=php /var/www/html/posts/api/artisan queue:work --tries=3 --verbose --timeout=30 --sleep=3
We can define many "programs" such as queue:work. Each has a block in a file called supervisord.conf. Every program has a command option which defines the command that needs to be run. In this case, it's the queue:work but with the full artisan path.
As I said, it can scale up processes:
[program:worker]
command=php /var/www/html/posts/api/artisan queue:work --queue=default,notification --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
In this example, it'll start two separate worker processes. They both can pick jobs from the queue independently from each other. This is similar to when you open two terminal windows and start two queue:work processes on your local machine.
Supervisor will log the status of the processes. But if we run the same program (worker) in multiple instances it's a good practice to differentiate them with "serial numbers" in their name:
[program:worker]
command=php /var/www/html/posts/api/artisan queue:work --queue=default,notification --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
process_name=%(program_name)s_%(process_num)02d
%(program_name)s will be replaced with the name of the program (worker), and %(process_num)02d will be replaced with a two-digit number indicating the process number (e.g. 00, 01, 02). So when we run multiple processes from the same command we'll have logs like this:
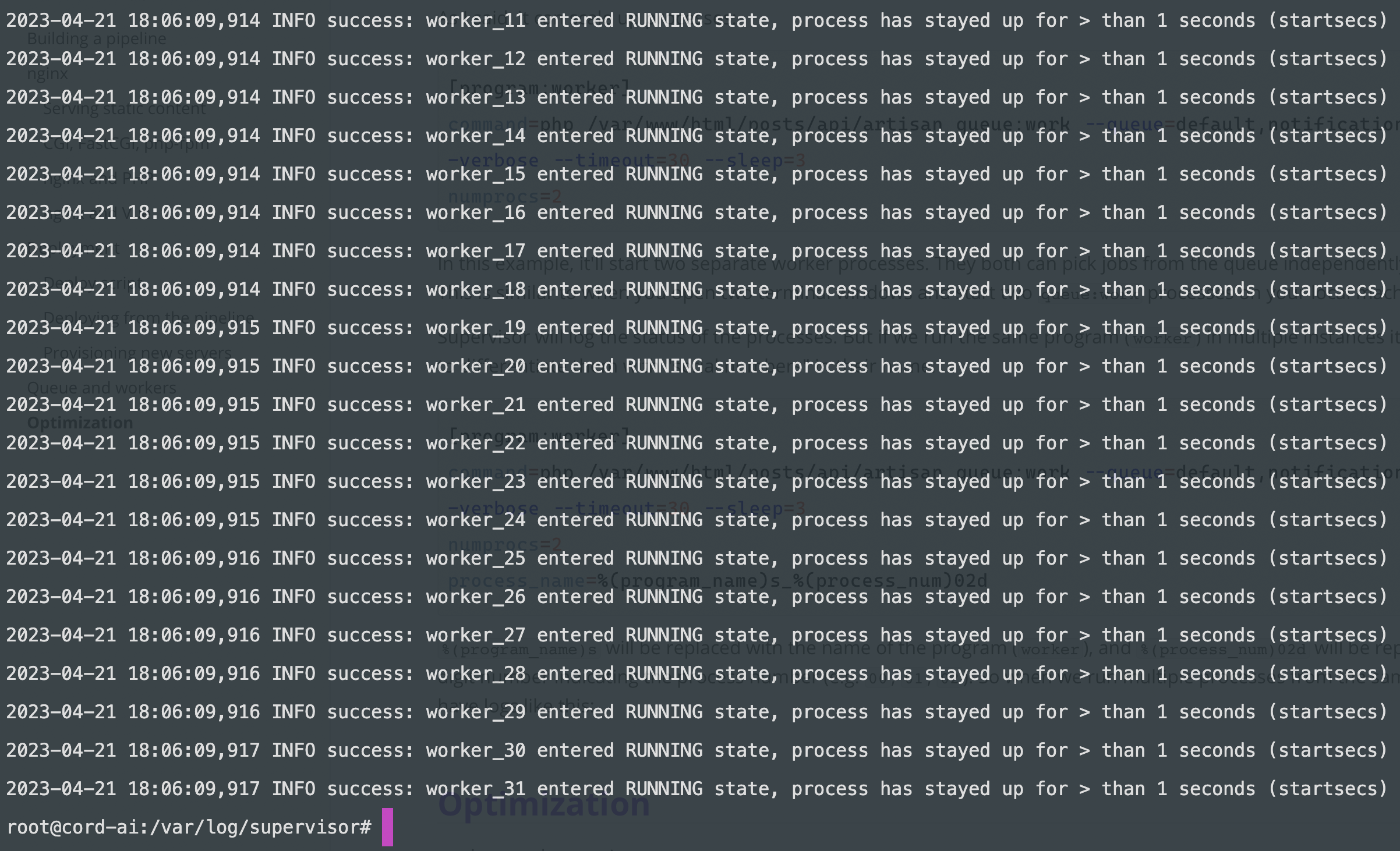
Next we can configure ho supervisor supposed to start or restart the processes:
[program:worker]
command=php /var/www/html/posts/api/artisan queue:work --queue=default,notification --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
process_name=%(program_name)s_%(process_num)02d
autostart=true
autorestart=true
autostart=true tells supervisor to start the program automatically when it starts up. So when we start supervisor (for example when deploying a new version) it'll automatically start the workers.
autorestart=true tells supervisor to automatically restart the program if it crashes or exits. Worker processes usually take care of long-running heavy tasks, often communicating with 3rd party services. It's not uncommon that they crash for some reason. By setting autorestart=true we can be sure that they are always running.
Since we start two processes from queue:work it'd be great if we could treat them as one:
[program:worker]
command=php /var/www/html/posts/api/artisan queue:work --queue=default,notification --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
process_name=%(program_name)s_%(process_num)02d
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true
stopasgroup=true tells supervisor to stop all processes in the same process group as this one (queue:work) when it stops.
killasgroup=true tells supervisor to send a kill signal to all processes in the same process group as this one (queue:work) when it stops.
These option basically mean: stop/kill all subprocesses as well when the parent process (queue:work) stops/dies.
As I said, errors happen fairly often in queue worker, so it's a good practice to think about them:
[program:worker]
command=php /var/www/html/posts/api/artisan queue:work --queue=default,notification --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
process_name=%(program_name)s_%(process_num)02d
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true
redirect_stderr=true
stdout_logfile=/var/log/supervisor/worker.log
redirect_stderr=true tells supervisor to redirect standard error output to the same place as standard output. We treat errors and info messages the same way.
stdout_logfile=/var/log/supervisor/worker.log tells supervisor where to write standard output for each process. Since we redirect stderr to stdout we'll have one log file to every message:
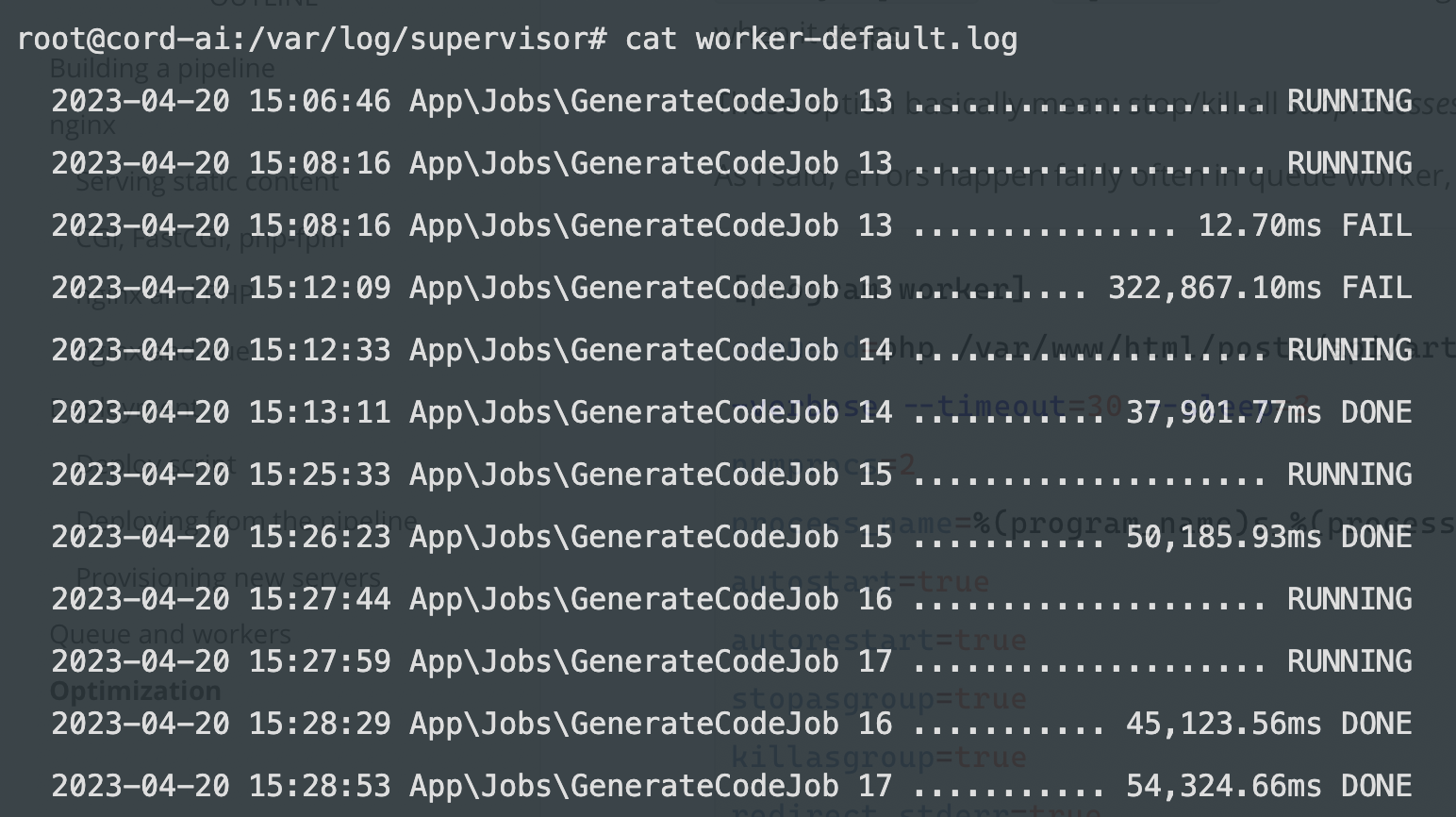
That was all the worker-specific configuration we need but supervisor itself also need some config in the same supervisord.conf file:
[supervisord]
logfile=/var/log/supervisor/supervisord.log
pidfile=/run/supervisord.pid
logfile=/var/log/supervisor/supervisord.log tells supervisor where to write its own log messages. This log tile contains information about the different programs and processes it manages. You can see the screenshot above.
pidfile=/run/supervisord.pid tells supervisor where to write its own process ID (PID) file. These files are usually located in the run directory:
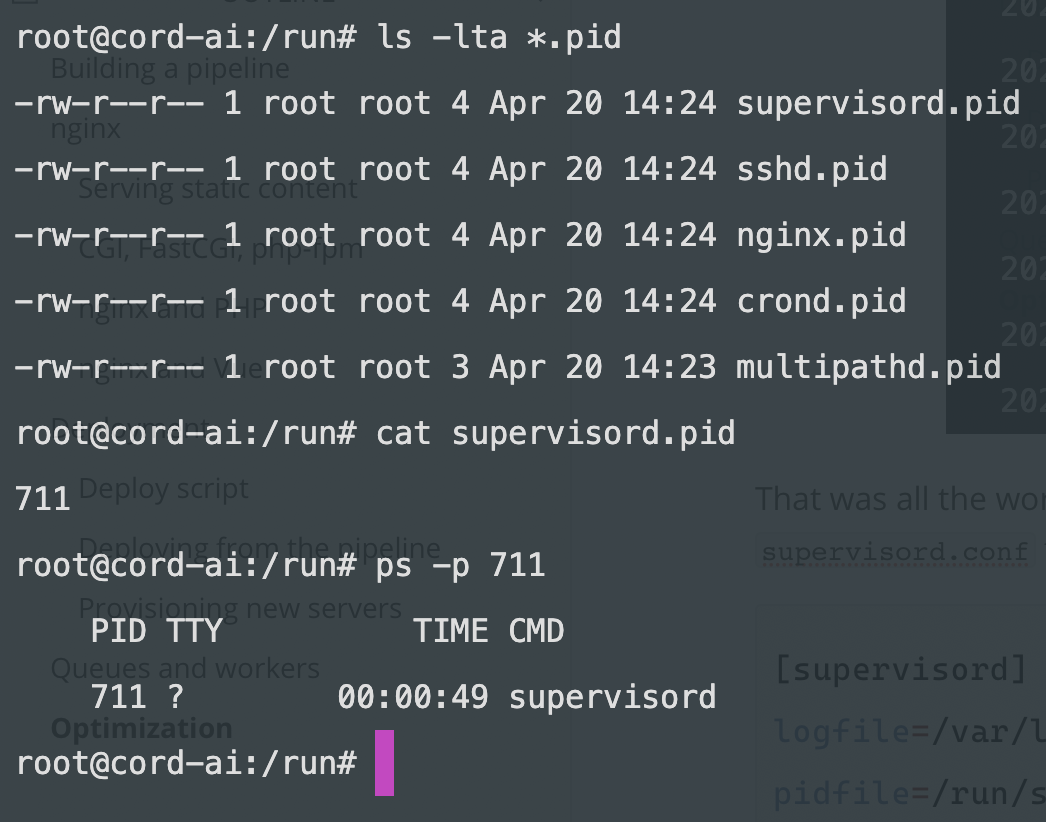
By the way, PID files on Linux are similar to a MySQL or Redis database for us, web devs.
They are files that contain the process ID (PID) of a running program. They are usually created by daemons or other long-running processes to help manage the process.
When a daemon or other program starts up, it will create a PID file to store its own PID. This allows other programs (such as monitoring tools or control scripts) to easily find and manage the daemon. For example, a control script might read the PID file to determine if the daemon is running, and then send a signal to that PID to stop or restart the daemon.
And finally, we have one more config:
[supervisorctl]
serverurl=unix:///run/supervisor.sock
This section sets some options for the supervisorctl command-line tool. supervisorctl is used to control Supervisor. With this tool we can list the status of processes, reload the config, or restart processes easily. For example:
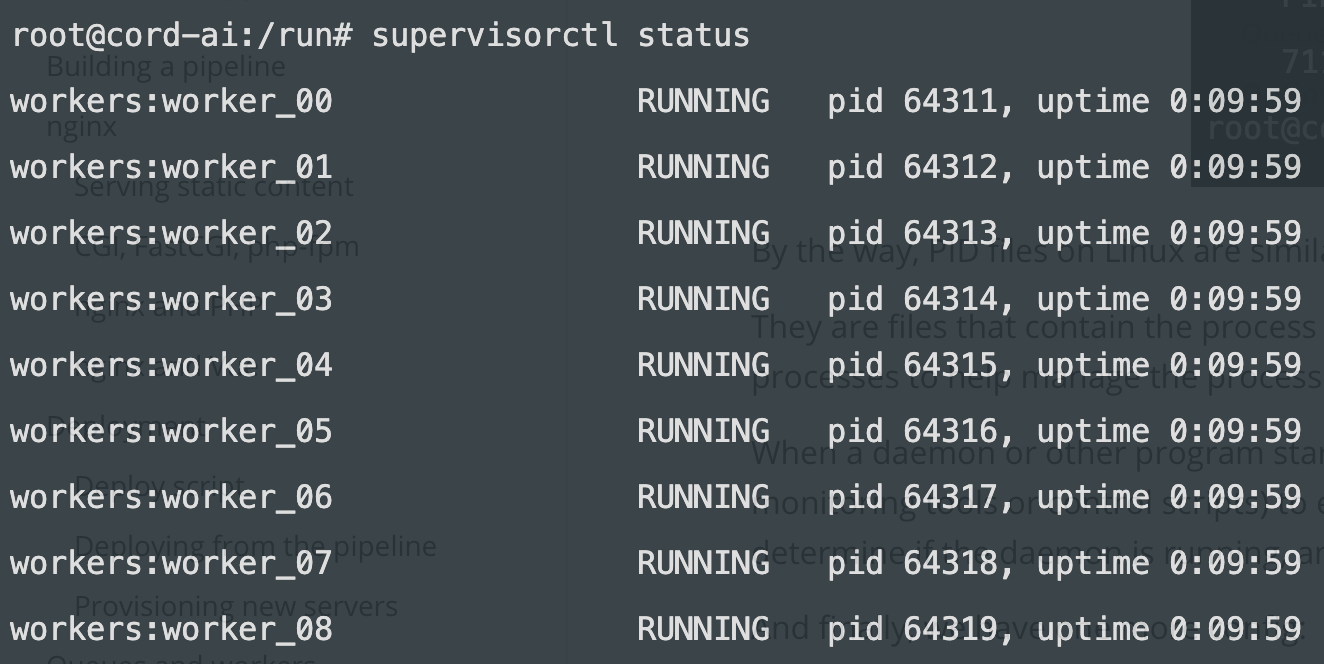
supervisorctl status
Returns a list such as this:
And finally, the serverurl=unix:///run/supervisor.sock config tells supervisorctl to connect to supervisor using a Unix socket. We've already used a Unix socket when we connected nginx to php-fpm. This is the same here. supervisorctl is "just" a command-line tool that provides better interaction with supervisor and its processes. It needs a way to send requests to supervisor.
This whole article comes from my new 465-page book called DevOps with Laravel. In the book, I'm talking about:
- Fundamentals such as nginx, CGI, FastCGI, FPM
- Backup and restore scripts
- Optimization
- CI/CD pipelines
- Log management and monitoring
- Docker and docker-compose
- Docker Swarm
- Kubernetes
- Serverless and PaaS
- ...and more

Multiple queues and priorities
Before we move on to actually running the workers let's talk about having multiple queues and priorities. First of all, multiple queues do not mean multiple Redis or MySQL instances.
- connection: this is what Redis or MySQL is in Laravel-land. Your app connects to Redis so it's a connection.
- queue: inside Redis we can have multiple queues with different names.
For example, if you're building an e-commerce site, the app connects to one Redis instance but you can have at least three queues:
- payments
- notifications
- default
Since payments are the most important jobs it's probably a good idea to separate them and handle them with priority. The same can be true for notifications as well (obviously not that important as payments but probably more important than a lot of other things). And for every other task you have a queue called default. These queues live inside the same Redis instance (the same connection) but under different keys (please don't quote me on that).
So let's say we have payments, notifications, and the default queue. Now, how many workers do we need? What queues should they be processing? How we prioritize them?
A good idea can be to have dedicated workers for each queue, right? Something like that:
[program:payments-worker]
command=php artisan queue:work --queue=payments --tries=3 --verbose --timeout=30 --sleep=3
numprocs=4
[program:notifications-worker]
command=php artisan queue:work --queue=notifications --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
[program:default-worker]
command=php artisan queue:work --queue=default --tries=3 --verbose --timeout=30 --sleep=3
numprocs=2
And then when you dispatch jobs you can do this:
ProcessPaymentJob::dispatch()->onQueue('payments');
$user->notify(
(new OrderCompletedNotification($order))->onQueue('notifications');
);
// default queue
CustomersExport::dispatch();
Alternatively, you can define a $queue in the job itself:
class ProcessPayment implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
public $queue = 'payments';
}
By defining the queue in the job you can be 100% sure that it'll always run in the given queue so it's a safer option in my opinion.
And now, the following happens:
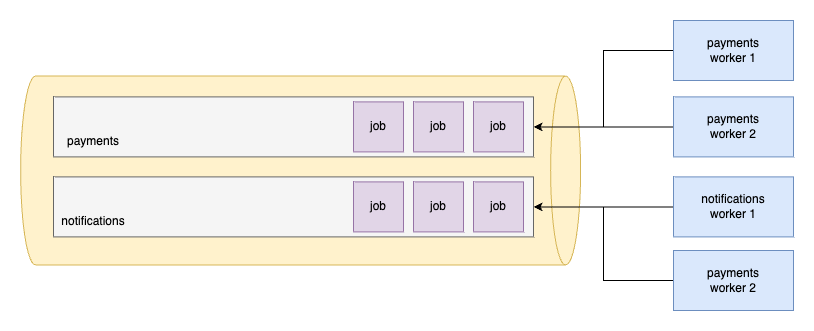
So the two (in fact three because there's also the default) are being queues at the same time by dedicated workers. Which is great, but what if something like that happens?
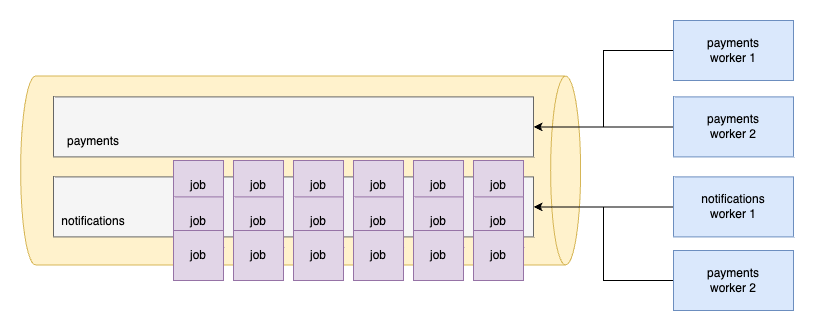
There are so many jobs in the notifications queue but none in the payments. If that happens we just waste all the payments worker processes since they have nothing to do. But this command doesn't let them to processes anything else:
php artisan queue:work --queue=payments
This means they can only touch the payments queue and nothing else.
Because of that problem I don't recommend you to have dedicated workers for only one queue. Instead prioritize them!
We can do this:
php artisan queue:work --queue=payments,notifications
The command means that if there are jobs in the payments queue, these worker can only process them. However, if the payments queue is empty, they can pick up jobs from the notifications queue as well. And we can do the same for the notifications workers:
php artisan queue:work --queue=notifications,payments
Now if the payments queue is empty this will happen:
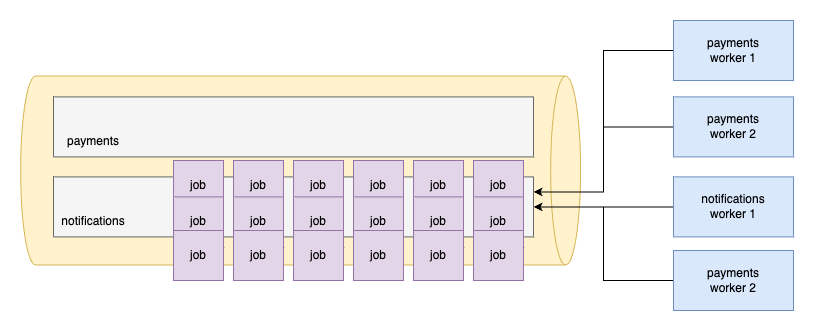
Now payments workers also pick up jobs from the notifications so we don't waste precious worker processes. But of course, if there are payments job they prioritize them over notifications:
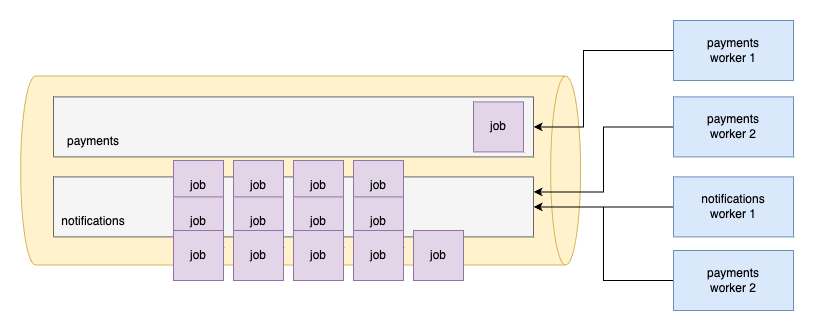
In this example, only one payment job came in so one worker is enough to process it.
All of this managed by Laravel!
And of course we can prioritize three queues as well:
# payment workers
php artisan queue:work --queue=payments,notifications,default
# notification workers
php artisan queue:work --queue=notifications,payments,default
# other workers
php artisan queue:work --queue=default,payments,notifications
With this setup we cover almost any scenarios:
- If there are a lot of payment jobs possibly three workers (more than three processes, of course) will process them.
- If there isn't any important job (payment or notification) there are a lot of workers available for default jobs.
- And we also cover the notifications queue.
And now let's deploy them!
Deploying workers
You should store the supervisor config in your repository. In this article, I assume that there is a deployment folder in the git repo so the file lives under the /deployment/config/supervisor folder. When deploying the project we only need to do three things:
- Copy the config file
- Update the config
- Restart all worker processes
By restarting all worker processes I mean we need to restart all programs (such as worker-notifications and worker-default) one-by-one. To make this step a bit easier supervisor let us declare program groups:
[group:workers]
programs=default-worker,notifications-worker
We can put programs into a group so when interacting with supervisorctl we can treat them as one program. These are the three steps you need to do in your deploy script:
cp $PROJECT_DIR"/deployment/config/supervisord.conf" /etc/supervisor/conf.d/supervisord.conf
# update the config
supervisorctl update
# restart workers (notice the : at the end. it refers to the process group)
supervisorctl restart workers:
Please notice the : symbol at the end of workers: It means we refer to the group called workers. With this one command we can restart multiple programs. That's it! Now supervisor will start the worker processes and log everything inside /var/log/supervisor.
Optimizing worker processes
Number of worker processes
That's a tricky question, but a good rule of thumb: run one process for each CPU core.
But of course itl depends on several factors, such as the amount of traffic your application receives, the amount of work each job requires, and the resources available on your server.
As a general rule of thumb, you should start with one worker process per CPU core on your server. For example, if your server has 4 CPU cores, you might start with 4 worker processes and monitor the performance of your application. If you find that the worker processes are frequently idle or that there are jobs waiting in the queue for too long, you might consider adding more worker processes.
It's also worth noting that running too many worker processes can actually decrease performance, as each process requires its own memory and CPU resources. You should monitor the resource usage of your worker processes and adjust the number as needed to maintain optimal performance.
However, there are situations when you can run more processes than the number of CPUs. It's a rare case, but if you're jobs don't do much work on your machine you can run more processes. For example, I have a project where every job sends API requests and then returns the results. These kinds of jobs are not resource-heavy at all since they do not run much work on the actual CPU or disk. But usually jobs are much resource heavy processes so don't overdo it.
Memory and CPU considerations
Queued jobs can cause some memory leaks. Unfortunately, I don't know the exact reasons but not everything is detected by PHP's garbage collector. As time goes, and your worker processes more jobs it uses more and more memory.
Fortunately, the solution is simple:
php artisan queue:work --max-jobs=1000 --max-time=3600
--max-jobs tells Laravel that this worker can only process 1000 jobs. After it reaches the limit it'll be shut down. Then memory will be freed up and supervisor restarts the worker.
--max-time tells Laravel that this worker can only live for an hour. After it reaches the limit it'll be shut down. Then memory will be freed up and supervisor restarts the worker.
These two options can save us some serious trouble.
Often times we run workers and nginx on the same server. This means that they use the same CPU and memory. Now, imagine what happens if there are 5000 users in your application and you need to send a notification to everyone. 5000 jobs will be pushed onto the queue and workers start processing them like there's no tomorrow. Sending notifications it's too resource-heavy, but if you're using database notifications as well, it means at least 5000 queries. Let's say the notification contains a link to your and users start to come in to your site. nginx has little resources to use since your workers eat up your server.
One simple solution to give a higher nice value to your workers:
nice -n 10 php artisan queue:work
These values can go from 0-19 and a higher value means a lower priority to the CPU. This means that your server will prioritize nginx or php-fpm processes over your worker processes if there's a high load.
Another option is to use the rest flag:
php artisan queue:work --rest=1
This means the worker will wait 1 second after it finishes with a job. So your CPU have an opportunity to server nginx or fpm processes.
So this is what the final command looks like:
nice -n 10 php /var/www/html/posts/api/artisan queue:work --queue=notifications,default --tries=3 --verbose --timeout=30 --sleep=3 --rest=1 --max-jobs=1000 --max-time=3600
I never knew about nice or rest before reading Mohamed Said's amazing book Laravel Queues in Action.
All of these examples and content come from my new 465-page book "DevOps with Laravel". Check it out: