« back published by Martin Joo on August 7, 2025
Estimating system requirements
- Pentium® 233 or equivalent
- DirectX video card with 800 x 600 resolution
- 32 MB RAM
- 4X CD-ROM drive
- 650 MB available hard drive space
Oh sorry, these are the system requirements of Diablo II
What a legendary game... But today, let's talk about more modern web applications.
On the 9th of September I'll launch a new book, System Design with Laravel
Estimating storage and compute capacity is an important aspect of designing new systems.
In this article, we're going to estimate the system requirements of an oversimplified order management system. This imaginary system has only two features:
- Processing an order
- Storing it
These are the two most crucial features in every sales-related application.
Let's say our system needs to handle 100,000 orders per day.
This means the following numbers:
-
100,000 orders/day
-
3,000,000 orders/month
-
36,500,000 orders/year
Let's say, on average, there are 10 items per order:
-
1,000,000 order items/day
-
30,000,000 order items/month
-
365,000,000 order items/year
If we plan for the next five years, we need to build an architecture that handles:
- 182,500,000 orders
- 1,825,000,000 order items
Storing orders
The question is: where do we start? First, we can estimate the size of the database.
This is the entire order_items table:
| Column | Type | Size (bytes) |
|---|---|---|
| ID | bigint | 8 |
| order_id | bigint | 8 |
| product_id | bigint | 8 |
| quantity | int | 4 |
| unit_price | int | 4 |
| created_at | timestamp | 4 |
| updated_at | timestamp | 4 |
| 40 bytes overall |
An order_items record takes about 40 bytes.
This is the orders table:
| Column | Type | Size (bytes) |
|---|---|---|
| ID | bigint | 8 |
| user_id | bigint | 8 |
| total | int | 4 |
| created_at | timestamp | 4 |
| updated_at | timestamp | 4 |
| 28 bytes overall |
An orders record takes about 28 bytes.
But this is not the entire size. Databases store all kinds of metadata, extra flags, index data, etc, for records and tables.
To get a better idea, in MySQL, we can run the following query:
show table status like 'orders'
The Avg_row_length column gives us a better estimation. In my case, it's 81 bytes
For the order_items table, it's 148 bytes
Given these numbers, we can make a better estimation:
Number of records in orders | Size |
|---|---|
| 1,000 | 81KB |
| 10,000 | 810KB |
| 100,000 | 8.1MB |
| 1,000,000 | 81MB |
| 10,000,000 | 810MB |
| 100,000,000 | 8.1GB |
| 185,000,000 | 15GB |
15GB to store the orders. Now let's see the items:
Number of records in orders | Size |
|---|---|
| 1,000 | 148KB |
| 10,000 | 1.4MB |
| 100,000 | 14MB |
| 1,000,000 | 140MB |
| 10,000,000 | 1.4GB |
| 100,000,000 | 14GB |
| 1,850,000,000 | 273GB |
It takes about 300GB of space to store 5 years' worth of orders and order items in the database. But it's a very optimistic (in other words, bad) estimation.
Over time, the number of columns will grow. The number of features will grow. New requirements will come in with new columns, tables, relationships, indexes, etc.
So a better estimation would be 1TB.
Storing files
Each order will have an invoice as a PDF. Invoices cannot be generated on the fly. The system needs to create them right after the order is created, and it needs to store them for a long time.
Let's say an average PDF invoice is 70KB in the system. In this case, storing 185,000,000 invoices takes about 13TB of space.
Another important aspect of an e-commerce-related system is pictures. Let's assume each product has about 10MB of pictures. And there are 1,000 products on the platform. The app needs an additional 10GB for the images. Which is negligible in this case, because the number of products doesn't grow with the number of orders. If your application has user-generated content, that's another story.
Based on these numbers, the system needs about 15TB of space to store everything. This doesn't account for other things like:
- Audit logs
- Access logs
- Queues
- Other metadata we don't know about now
- etc
You should always add some margin of safety. The more uncertain the situation, the bigger your margin should be. Right now, it's a 5-year estimation. Lots of things can change in 5 years (think about all the weird things that took place between 2020-2025).
The original 15TB can easily be doubled or tripled. Let's call it 30TB.
The minimum storage requirements
This is a 5-year estimation. At the beginning, you obviously don't need to buy 30TB of storage to run a system that needs 5GB.
To start our project and run it for 12 months, we need the following:
- 50GB for 36M orders and 365M order items
- 3TB for 36M invoices
- 10GB for images
It's safe to assume that 3-5TB of storage is more than enough for the first 6-12 months (with an extra margin of safety).
The required number of workers
In most applications, it's a good idea to identify the most crucial workflows and implement them using queues and workers.
In this app, handling orders is the most important feature. It has to be reliable.
Why do we need a queue and workers?
Of course, you can handle orders synchronously. There are a few drawbacks to that:
- Handling an order takes more time than a typical HTTP request. In this case, it's 1.2s - 2s. By a typical HTTP request, I mean something like 200ms or 400ms.
- Handling orders in an async way is more reliable. If something goes wrong while processing the order, you'll have a failed job that you can retry later. It is a built-in feature in most queue systems. If you use a simple request-response model, you lose that mechanism. Also, if there are problems with the workers, you won't lose the order. It'll be placed in the queue.
- If the API is synchronous and the system is overloaded, your users will probably experience timeouts, and orders will be lost. In an async setup, even if the system is overloaded, there's a good chance that jobs will be put into the queue. You won't lose orders. Which is a big win.
- If there's a bug in your current deployment and orders fail, in a sync setup, you'll lose the failed orders. Users will have a bad experience. In an async setup, orders will fail, but you won't lose them. They simply become failed jobs that can be re-run when you deploy the fix.
Having a queue system has multiple advantages. And they are all "free." Meaning, you don't need to spend extra hours to have these safety features. They are built into most queue systems.
Let's play a quick game.
100,000 orders/day is 4,166 orders/hour or 70 orders/minute. It's 1.2 orders/second.
Given the fact that one order takes 2s to process, how many workers do we need to handle 100,000 orders a day?
Assuming a perfect distribution of jobs. Every second, a new order comes in.
Take a break and try to answer the question.
The answer is two.
In my tests, an average PDF generation took about 1s. The overall order creation took about 1.2s. This assumes everything runs smoothly. Let's call it 2s.
Using one worker, it's impossible to run 1.2 jobs per second when a job takes 2s to finish. It's possible, but quite painful:
| Job ID | Comes in | Starts at | Ends at | Runtime |
|---|---|---|---|---|
| 1 | 2:00:00 | 2:00:00 | 2:00:02 | 2s |
| 2 | 2:00:01 | 2:00:02 | 2:00:04 | 3s |
| 3 | 2:00:02 | 2:00:04 | 2:00:06 | 4s |
| 4 | 2:00:03 | 2:00:06 | 2:00:08 | 5s |
| 5 | 2:00:04 | 2:00:08 | 2:00:10 | 6s |
| ... | ||||
| 10 | 2:00:09 | 2:00:18 | 2:00:20 | 11s |
The 5th job would take 6s to finish instead of 2s. The 10th job would take 11s. The actual work still takes 2s, but it spends an extra 9s in the queue pending.
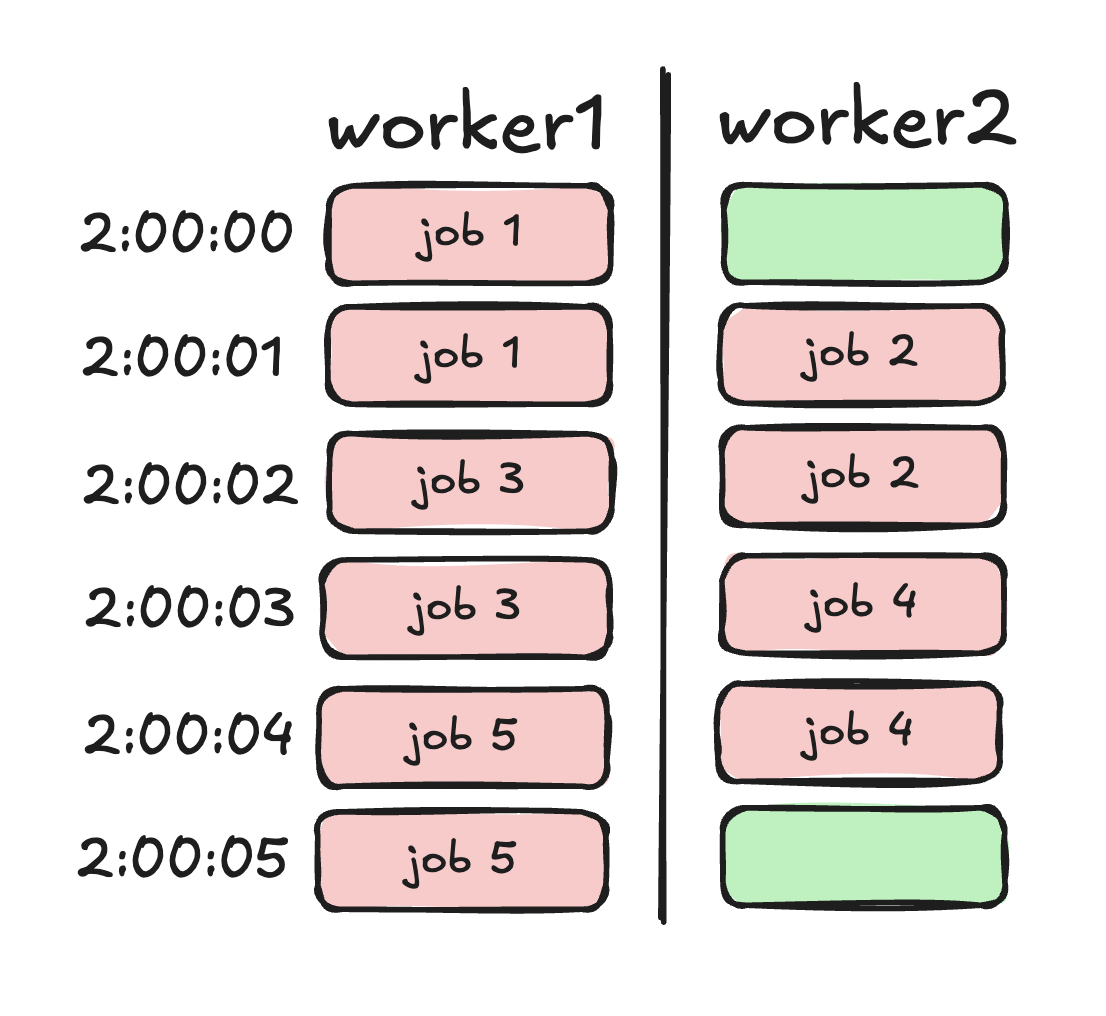
With two workers:
| Job ID | Worker ID | Comes in | Starts at | Ends at | Runtime |
|---|---|---|---|---|---|
| 1 | 1 | 2:00:00 | 2:00:00 | 2:00:01 | 2s |
| 2 | 2 | 2:00:01 | 2:00:01 | 2:00:02 | 2s |
| 3 | 1 | 2:00:02 | 2:00:02 | 2:00:03 | 2s |
| 4 | 2 | 2:00:03 | 2:00:03 | 2:00:04 | 2s |
| 5 | 1 | 2:00:04 | 2:00:04 | 2:00:05 | 2s |
Of course, this is a bit tight. Both workers are utilized at close to 100%. There's very little idling.
Let's visualize it:
If one of the workers slows down a bit, it will affect all the jobs, and there's going to be a huge delay after a few hundred jobs.
worker1's utilization is 100% while worker2's utilization is about 66%. The overall utilization is 83%. There's very little built-in safety in this setup.
We can add an extra worker to have some breathing room:
| Job ID | Worker ID | Comes in | Starts at | Ends at | Runtime |
|---|---|---|---|---|---|
| 1 | 1 | 2:00:00 | 2:00:00 | 2:00:01 | 2s |
| 2 | 2 | 2:00:01 | 2:00:01 | 2:00:02 | 2s |
| 3 | 3 | 2:00:02 | 2:00:02 | 2:00:03 | 2s |
| 4 | 1 | 2:00:03 | 2:00:03 | 2:00:04 | 2s |
| 5 | 2 | 2:00:04 | 2:00:04 | 2:00:05 | 2s |
| 6 | 3 | 2:00:05 | 2:00:05 | 2:00:06 | 2s |
Visualizing:
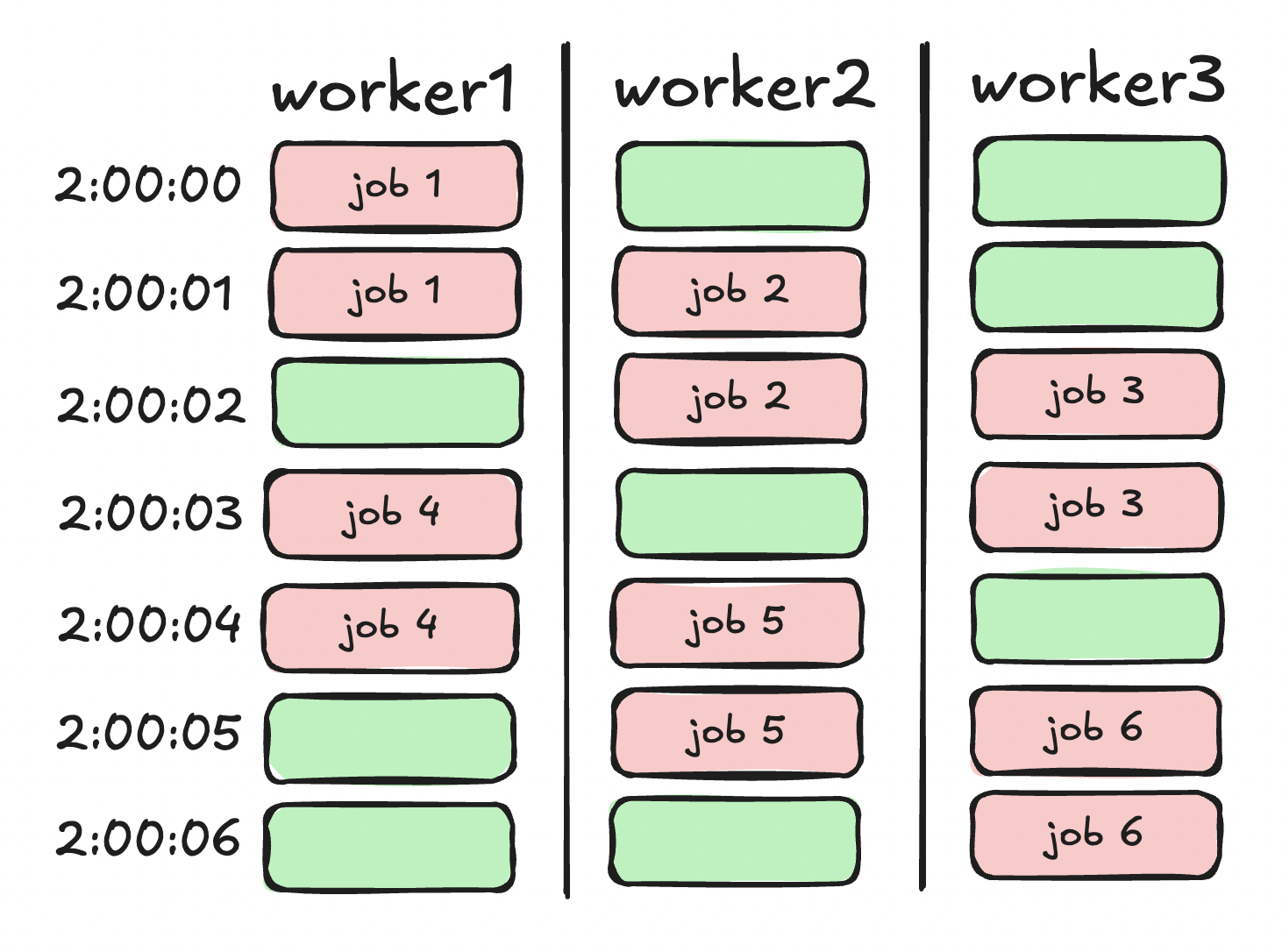
Now, each worker is utilized at 57%. If one of them fails or slows down, there's plenty of room to handle the situation.
This setup has more redundancy. Which is a trade-off. The 2-worker scenario costs you less, but it's more prone to error. The 3-worker setup costs you more, but it's more reliable.
Of course, you can autoscale your workers, but you still need to set up a minimum number of nodes.
Because the system has other queue jobs as well (such as exports), having four workers is probably a good starting point.
Four workers will also handle traffic spikes better. But the ultimate solution for that problem is autoscaling.
This entire article comes from my new book System Design with Laravel
