« back published by Martin Joo on January 4, 2024
DevOps With Laravel: Load Balancers from Scratch
Introduction
What is a load balancer? When I first learned about the topic I thought load balancer is an "exact thing," For example, an nginx config that balances load between servers. But as I learned more about this topic I realized that load balancer is a concept. It's not an exact thing/technology. It can be applied on multiple levels:
-
Your operating system's CPU scheduler is a load balancer. You probably have 8 or 16 cores but if you run
htopyou should see 100s of tasks. The most important task of the scheduler is to balance to load across the cores. It works on the hardware level. -
PHP FPM is a load balancer. It has one master process and many worker processes. The master process accepts requests and forwards them to the worker processes. So it's a load balancer that works on the process level.
-
nginx is a load balancer. I mean, the internal workings of nginx. It has a master process and many worker processes. It works the same way as FPM but it handles all kinds of HTTP requests. It balances requests across worker processes. It also works on the process level.
-
docker-compose is a load balancer. Yes, you can have multiple replicas of the same container with docker-compose. For example, you can have multiple replicas of your API container listening on the same port and then balance the load with a simple nginx load balancer. It also works on the process level. Or I should say "container-level."
-
Your Laravel queue is a kind of load balancer. Let's say you have 5 workers and 100 jobs. The jobs are distributed across the workers in order.
-
nginx is a load balancer. I mean, the user-facing part of nginx. You can implement a load balancer that distributes the traffic across multiple servers. You can run your load balancer on a dedicated server. It works on the server level.
-
Cloud providers offer managed load balancers. They are dedicated servers and usually run nginx or Traefik (which is a fancy nginx). It works on the server level.
-
And of course, Docker Swarm and Kubernetes have their own load balancer implementations (ingress). They work on the server/process level.
-
Your own algorithm can be a load balancer as well. For example, if you're working on an inventory management system. If a customer orders a product you need to choose a warehouse. You might implement a FIFO or LIFO algorithm. Or you select the warehouse that is closest to the customer. And of course, you need to check the quantities. Either way, you're balancing the "load" (orders) across warehouses. It works on the "business logic level."
So load balancing is not an exact thing or technology but a concept that can be applied in various situations. In this chapter, we're going to explore three different load balancers:
- Plain nginx balancing the load across VPSs
- docker-compose balancing the load across containers
- Managed load balancers balancing the load between VPSs
nginx as a load balancer
This is the bare minimum nginx configuration for a load balancer:
user www-data;
events {}
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}
We've already seen the proxy_pass directive. It just forwards a request to a given location. Earlier, we used it as a proxy. It forwarded requests to the frontend or the backend based on the URL.
In this case, it accepts every request that comes in to / and forwards them to the backend. Which is an upstream. It is used to define a group of servers that will handle incoming requests. In this example, the backend upstream defines a group of three servers: backend1.example.com, backend2.example.com, and backend3.example.com. Whenever you refer to http://backend you refer to the upstream which represents the three backend servers. nginx will balance the load across the three servers using the round-robin algorithm. Each backend server gets an equal amount of requests in circular order.
It looks like this:
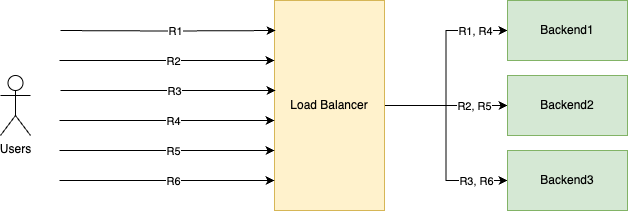
As you can see, it goes through the servers in a "circular order:"
- R1 gets handled by Backend1
- R2 gets handled by Backend2
- R3 gets handled by Backend3
- And then it starts over
- R4 gets handled by Backend1
- R5 gets handled by Backend2
- R6 gets handled by Backend3
In order to test it I created three DigitalOcean servers (each of them uses the LEMP image such as in the Fundamentals part):
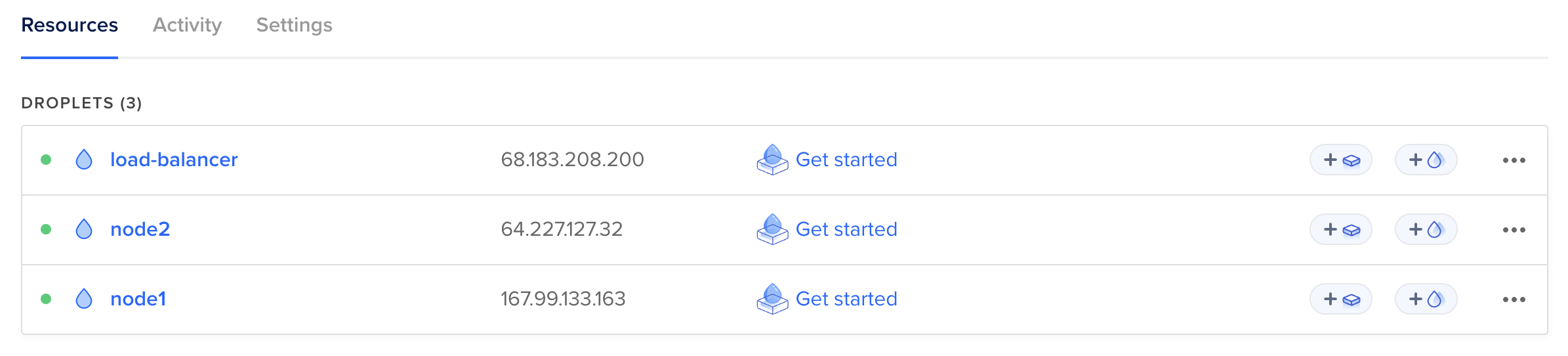
One the load balancer and two actual servers. I didn't buy a domain for this, so I'm using IP addresses:
upstream backend {
server 167.99.133.163;
server 64.227.127.32;
}
On the servers, I'll run a very simple PHP script:
<?php
echo json_encode([
'data' => [
'hostname' => gethostname(),
],
]);
It returns the hostname of the server such as node1 or node2.
To serve this PHP script we need a minimal nginx config on the servers:
server {
listen 80;
index index.php;
location / {
root /var/www/html;
include /etc/nginx/fastcgi.conf;
fastcgi_pass unix:/run/php/php8.0-fpm.sock;
fastcgi_index index.php;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
}
Everything you can see here is explained in the Fundamentals part. Every request is served by index.php which always returns the hostname.
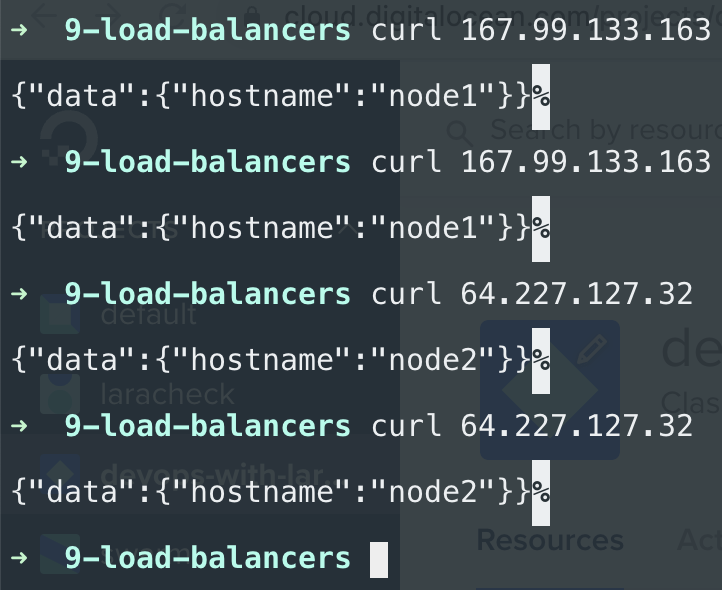
If I now hit node1 it always returns node1 and node2 responds with node2:
But if I hit the load balancer's IP address you can see it starts to distribute the traffic between the two nodes:
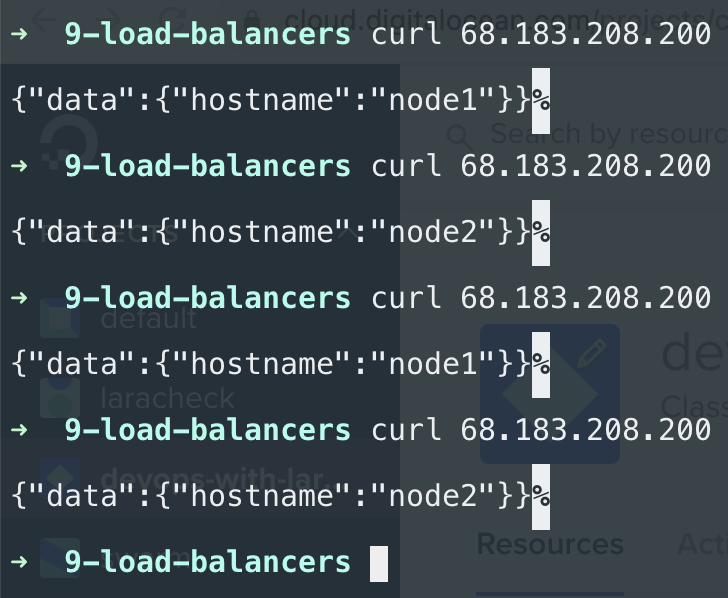
This is round-robin in action. Of course, it doesn't matter if you have only a single PHP file or a whole Laravel application. Load balancing is the same. You have a dedicated server with an nginx config that distributes the incoming traffic across your nodes.
This whole article comes from my new 465-page book called DevOps with Laravel. In the book, I'm talking about:
- Fundamentals such as nginx, CGI, FastCGI, FPM
- Backup and restore scripts
- Optimization
- CI/CD pipelines
- Log management and monitoring
- Docker and docker-compose
- Docker Swarm
- Kubernetes
- Serverless and PaaS
- ...and more

Managed load balancers
Every cloud provider offers managed load balancers. The main benefits are:
- You don't have to maintain your load balancer configuration. By maintaining, I mean, adding new servers to the upstream, changing domain names, etc. And of course having the actual server, upgrading it, restarting nginx when the configuration changes, etc.
- Better/easier monitoring. Managed load balancers offer load balancer-specific metrics/graphs by default.
- Built-in health checks.
- Cheap. On DigitalOcean it costs $12/month to have a managed load balancer that handles 10000 concurrent connections. Of course, you can achieve the same with a $6 droplet and a custom nginx configuration, but $12 is still pretty cheap, and in this case, 10000 is guaranteed.
- Scaling, high availability. You can have multiple replicas of your load balancer. So if you know that you need ~100000 concurrent requests you can just increase the number of nodes to 10. For $120/month you now can handle 100000 concurrent connections.
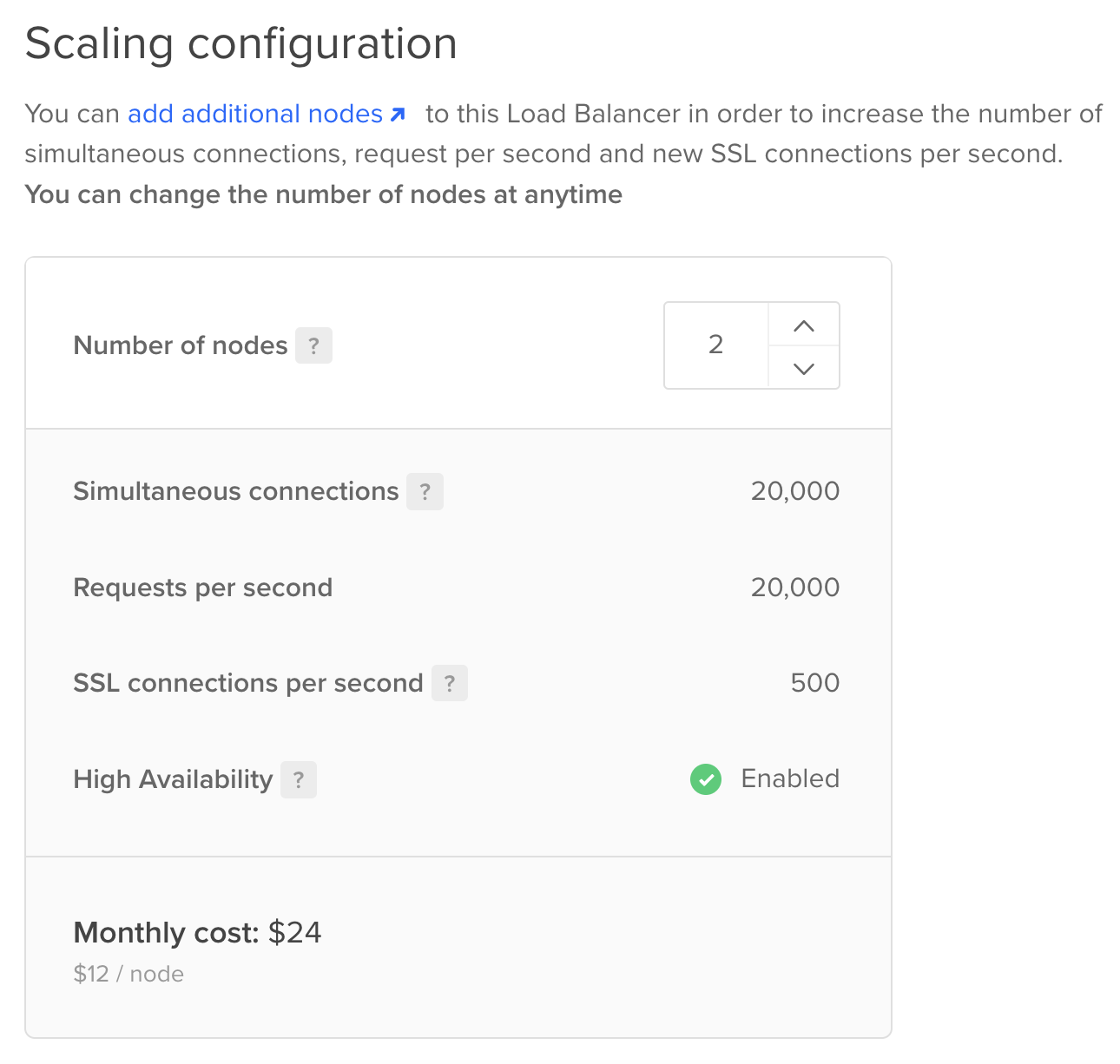
I'm going to use DigitalOcean again. You can find load balancers in the Networking nav item. This is what the scaling configuration looks like:
And this is the "upstream" configuration:
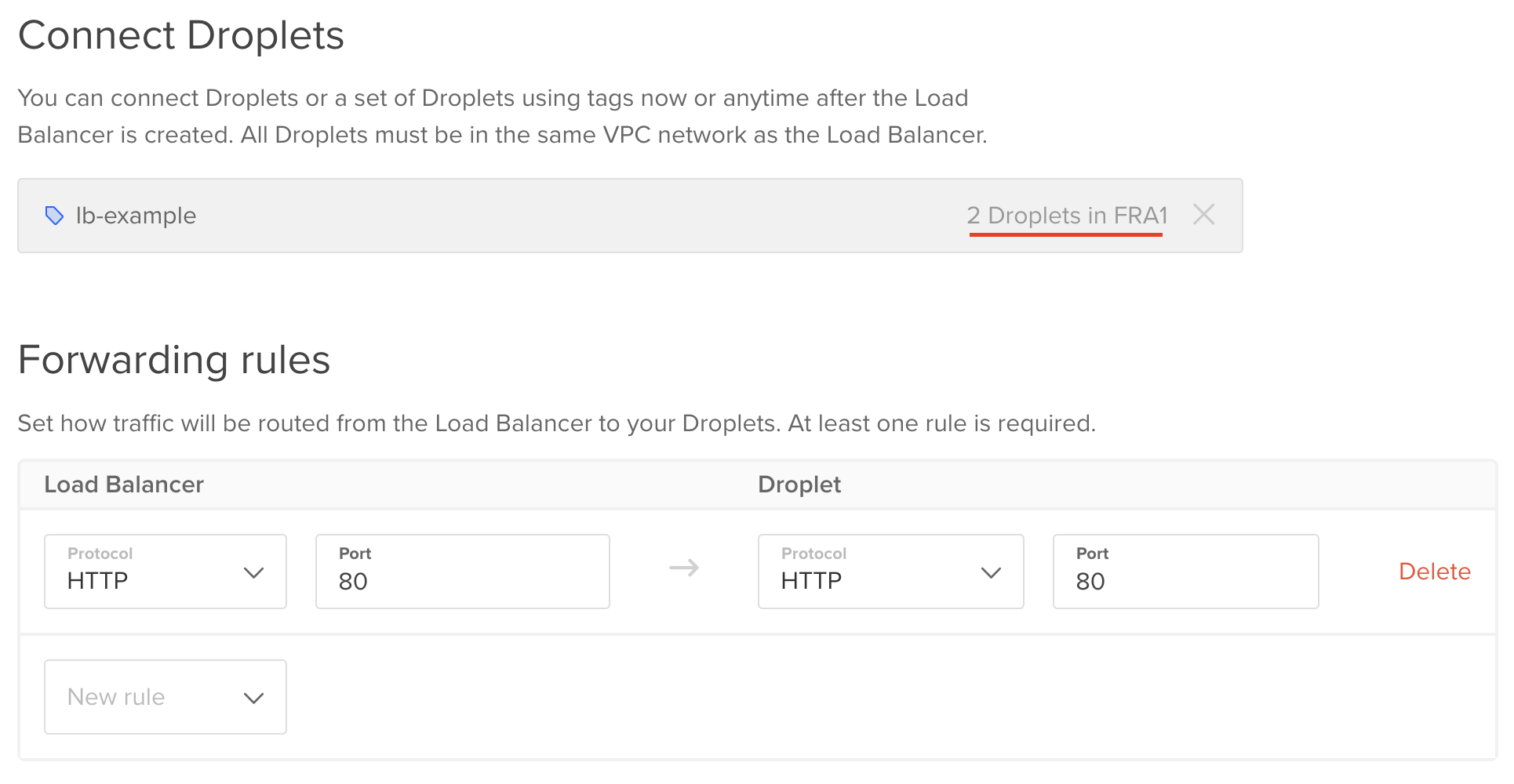
You can select particular droplets or tags as your upstream servers. In this example, I use the tag lb-example. As you can see, there are two droplets tagged as lb-example. Tags are great because you can just add or remove them to other servers and your load balancer will automatically apply these changes.
Forwarding rules are quite straightforward. In this case, the load balancer forwards incoming requests from port 80 to port 80 on the target droplets. Of course, you need to use port 443 if you set up a certificate (which I didn't do for this example).
And that's it! With just 3 minutes of setup, we have a load balancer that handles 20000 concurrent connections.
This is the dashboard:
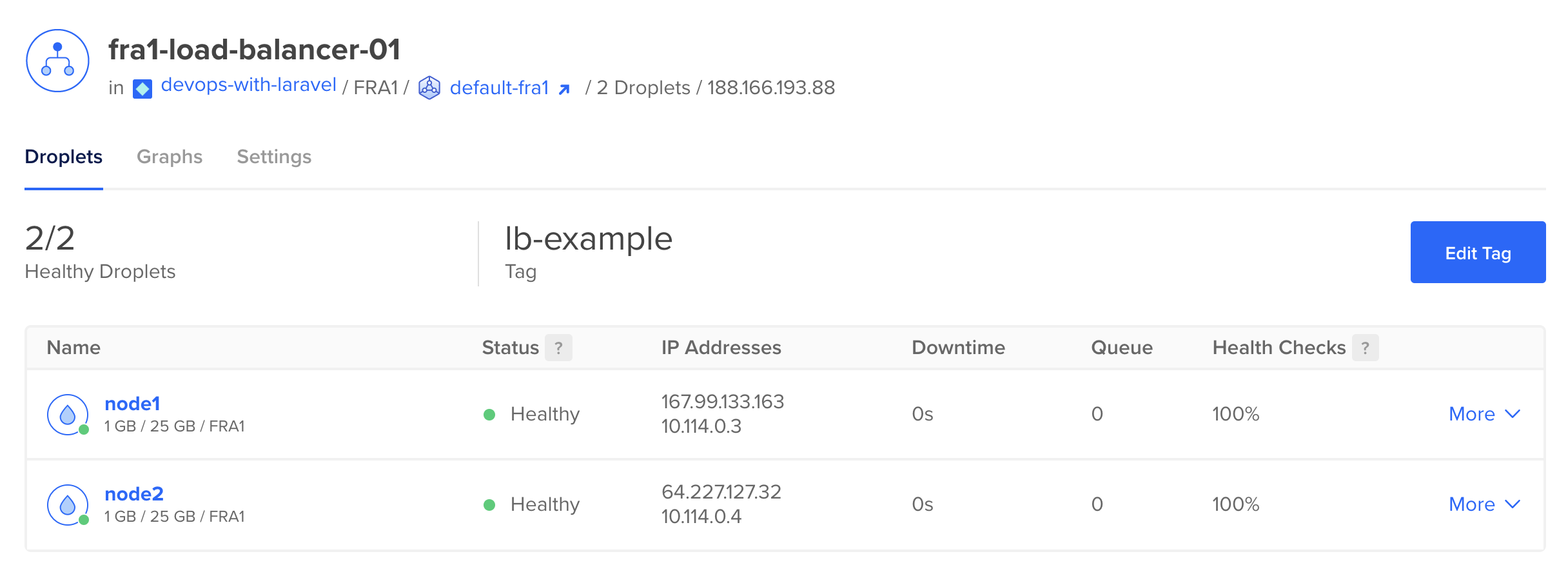
It figured out the exact droplets based on the tag which is a pretty good feature. You don't have to manually update any nginx configuration when you add a new server. You just tag your server which is pretty easily scriptable.
And of course, we have graphs as well:
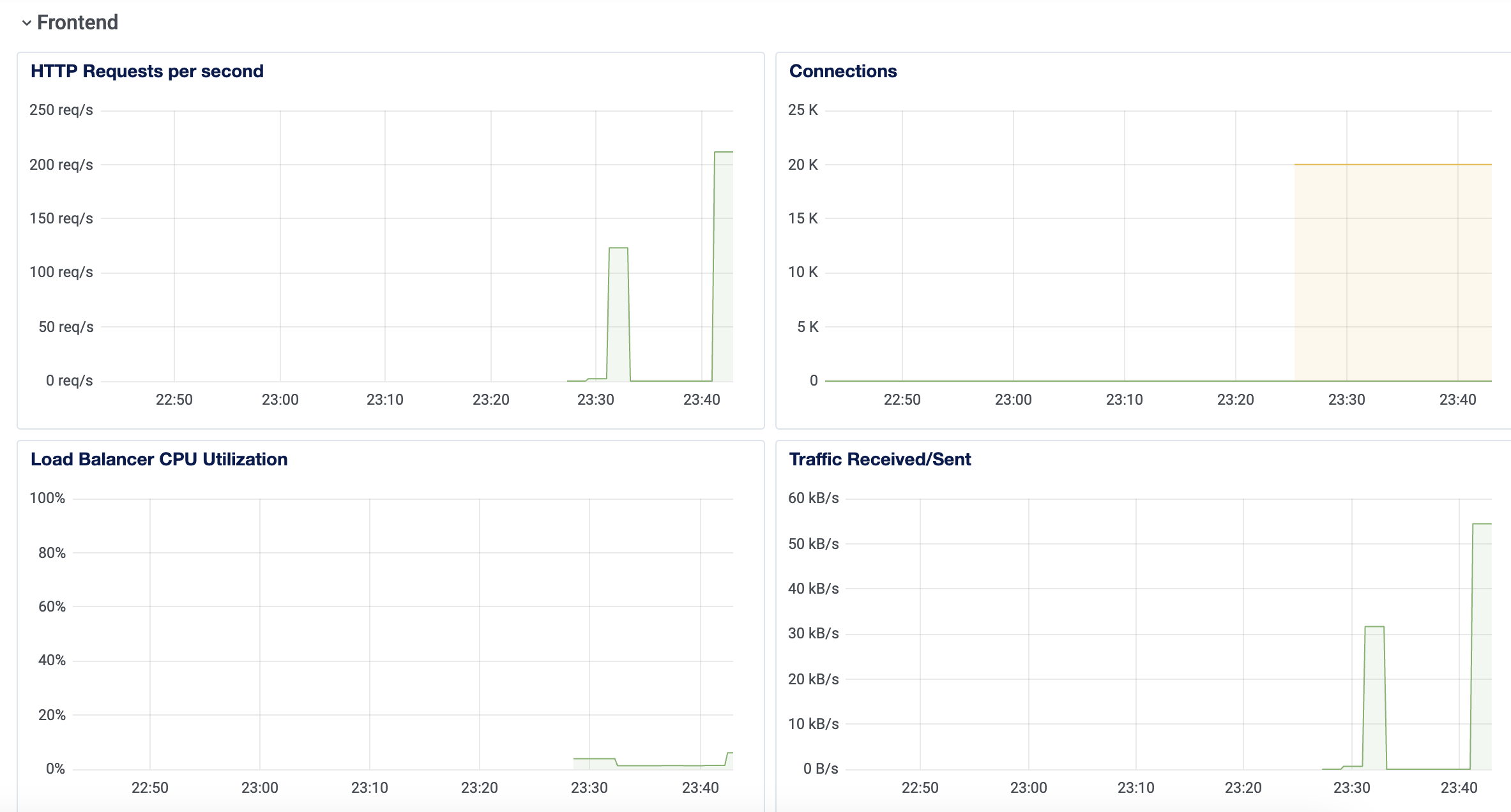
HTTP requests per second and connections are probably the most important ones.
Load balancing with docker-compose
As I said in the introduction, docker-compose can also be used as a load balancer. If you check out the documentation there are some commands under the deploy key that can be used with docker-compose even when you're not in Swarm mode. replicas is one of them:
version: '3.8'
services:
app:
build:
dockerfile: Dockerfile
context: .
deploy:
replicas: 2
ports:
- "8000"
If you run docker-compose up this is what happens:

The app service runs two containers: lb-app-1 and lb-app-2. We specified two replicas so docker-compose started two containers. Just like Swarm or Kubernetes.
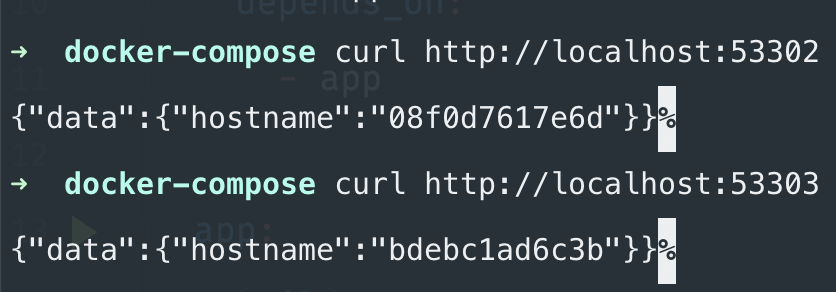
Both containers bind to a random port on the host machine. In my case, they are 64919 and 64965. When you define ports in a compose you have a number of options. The most popular is this: HOST:CONTAINER. This is exactly what we used earlier in the book. But you can omit the HOST port and specify only the container port with "8000". This means the container listens on port 8000 and docker-compose binds it to a random (high) port on the host machine. This is exactly what we need if we want to run a service in multiple replicas.
As you might expect, now we access the application on two different ports:
Now everything is ready to create a load balancer service that distributes the traffic between the two app containers. In this case, I'm going to use a simple nodejs server. I'm going to explain why at the end of the chapter, however, there's no real difference from the load balancer point of view.
But in this case, we don't need an upstream because we don't have multiple servers. It's just a simple proxy_pass to the app service:
http {
server {
listen 3000;
location / {
proxy_pass http://app:8000;
}
}
}
So nginx forwards the requests to app:8000. Since we wrote replicas: 2 in the compose file, docker-compose distributes the requests between the two replicas. We need another service for the load balancer as well:
load-balancer:
image: nginx:1.25-alpine
restart: unless-stopped
volumes:
- ./load-balancer.conf:/etc/nginx/nginx.conf:ro
ports:
- "3000:3000"
depends_on:
- app
This is what the whole process looks like:
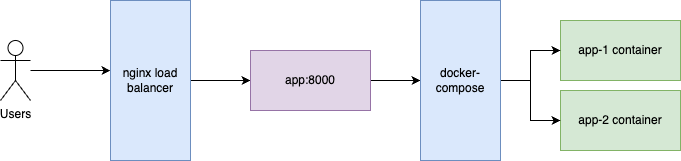
docker-compose acts like an internal load balancer for the containers. From nginx point of view, it only sees a regular domain name with a port that refers to the compose service.
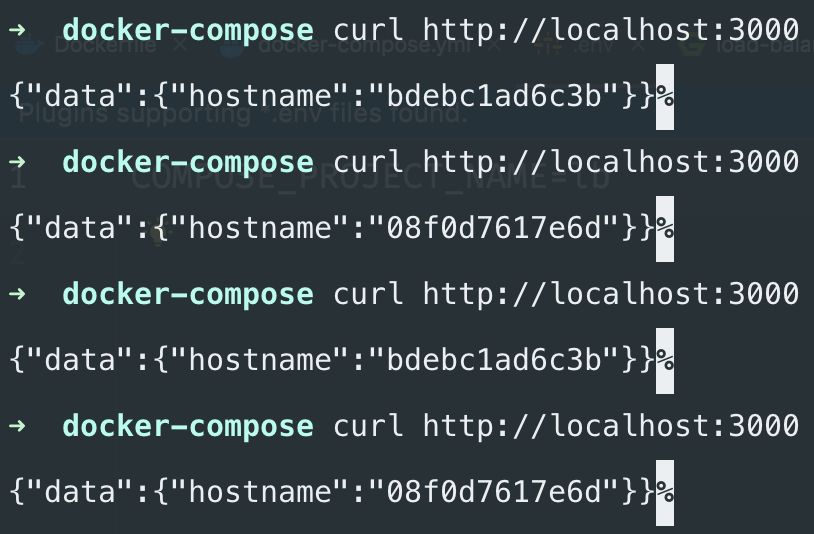
If you now try to hit the load balancer you can see the two containers serving the requests in a round-robin fashion:
This is the complete docker-compose file:
version: '3.8'
services:
load-balancer:
image: nginx:1.25-alpine
restart: unless-stopped
volumes:
- ./load-balancer.conf:/etc/nginx/nginx.conf:ro
ports:
- "3000:3000"
depends_on:
- app
app:
build:
dockerfile: Dockerfile
context: .
deploy:
replicas: 2
ports:
- "8000"
volumes:
- ./index.js:/usr/src/app/index.js
As I said earlier, in this example, I use a basic nodejs/express server instead of PHP or Laravel. The reason is simple. When you use PHP with FPM you already have this kind of load balancer. In the Fundamentals we discussed that FPM starts one master and many worker processes to server requests. What we did here is essentially the same. In our example, the load-balancer container is the master process and the two app containers are the worker processes. So if you use FPM you already have a load balancer that handles requests. If you add another load balancer with compose you'll probably hurt the performance of your server. Let's say your machine can run 20 FPM processes (calculated using the method I just showed you in the Fundamentals). But now you also replicate the container so your server runs X*20 FPM processes which can hurt your memory/CPU usage because it's X times more than the optimal. So if you use FPM you most likely don't need this kind of load balancing on top of that. However, it's an excellent way to scale nodejs services. Node doesn't have FPM, it uses a single thread, so it's an excellent candidate to scale with docker-compose which you can set up in ~30 minutes and doesn't require you to add new technologies to your existing stack.
Caching
One of the great things about load balancers is that all requests goes through them which means we can cache responses pretty easily. This cache can be implemented in nginx so the request doesn't need to hit the API at all. It means your response will be significantly faster than a Redis cache.
This is what it looks like:
user www-data;
events {
worker_connections 1024;
}
http {
proxy_cache_path /tmp/nginx-cache levels=1:2 keys_zone=cache:10m max_size=10g inactive=60m;
upstream backend {
server 167.99.133.163;
server 64.227.127.32;
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_cache cache;
proxy_cache_valid 200 302 1m;
proxy_cache_valid 404 30s;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_cache_lock_timeout 5s;
}
}
}
If you read the Fundamentals part (which you should) it looks pretty familiar. proxy_cache_path works the same as fastcgi_cache_path which is described in the Fundamentals part so I'm not going to repeat it.
proxy_cacheinstructs nginx to cache the responses from the backend server using thecachezone defined inproxy_cache_path.proxy_cache_validsets the caching time for specific response codes. In this example, 200 and 302 responses are cached for 1 minutes, 404 responses are cached for 30 seconds.proxy_cache_use_staleis used to control when to serve stale (expired) content from the cache in case there is an error or the backend server is not responding in a timely manner. In this example, 500, 502, 503, and 504 responses will be served from cache while the backend server is being updated or is down.proxy_cache_lockis used to control the locking behavior when multiple requests are attempting to refresh the same cache item simultaneously. When it'sononly one request will be able to refresh the cache item at a time.proxy_cache_lock_timeoutsets the maximum time a request will wait for the cache lock to be released before delivering the response directly from the backend server.
So this configuration caches every 200 responses from the servers. But it has some bad consequences as well. Let's say your API does not always returns the appropriate response code. Maybe it has some legacy parts, where POST requests do not return 201 but 200. If this is the case, you just cached every POST requests! The following happens:
- The client sends a
POSTrequest (for example, it creates a new product) - nginx calculates a hash value from the request based on the method, path, etc
- It checks if there's a cached response in the
/tmp/nginx-cachefolder defined inproxy_cache_path - It doesn't find anything so it forwards the requests to the backend
- The backend returns a
200response so nginx caches it and then return it to the client
Great, but the next time a user tries to send the same POST request they'll get served from the same cache for 10 minutes! So no POST requests will reach your actual server. It's obviously a bad thing.
There are two things you can do to avoid situations like this:
- Use the correct status codes.
POST,PATCH,PUT, orDELETErequests should not return200at all. - Bypass the cache entirely if it's not a
GETrequest.
I think the second option is way better and safer. And it'a actually pretty easy as well:
location / {
proxy_pass http://backend;
set $no_cache 0;
if ($request_method != GET) {
set $no_cache 1;
}
proxy_cache cache;
proxy_no_cache $no_cache;
proxy_cache_valid 200 302 1m;
proxy_cache_valid 404 30s;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_cache_lock_timeout 5s;
}
This is the same technique we used with fastcgi_cache in the Fundamentals part.
proxy_no_cache 1;tells nginx not to cache the current request.proxy_no_cache 0;tells nginx to cache the current request.
All we need to do is to set proxy_no_cache to 1 if the current request's method is GET:
set $no_cache 0;
if ($request_method != GET) {
set $no_cache 1;
}
And that's it! Now we have a super fast cache that stores only responses to GET requests with status code of 200, 302, or 404.
One more important thing about this kind of cache: you cannot cache user-dependent content. For example, if you handle multiple languages you probably cannot use a simple configuration such as this. Imagine a Hungarian speaking user sends you a request and gets a response from the server in Hungarian. The next user who requests the same URL gets the same response. So English speaking users will see responses in Hungarian. This also applies to permissions and visibility settings. If the response depends on the user's role you cannot use nginx proxy cache.
This whole article comes from my new 465-page book called "DevOps with Laravel." In the book, I'm talking about:
- Fundamentals such as nginx, CGI, FastCGI, FPM
- Backup and restore scripts
- Optimization
- CI/CD pipelines
- Log management and monitoring
- Docker and docker-compose
- Docker Swarm
- Kubernetes
- Serverless and PaaS
- ...and more