« back published by Martin Joo on April 23, 2024
Chunking Large Datasets
When it comes to working with larger datasets one of the best you can apply to any problem is chunking. Divide the dataset into smaller chunks and process them. It comes in many different forms. In this chapter, we're going review a few of them but the basic idea is always the same: divide your data into smaller chunks and process them.
Exports
Exporting to CSV or XLS and importing from them is a very common feature in modern applications.
I'm going to use a finance application as an example. Something like Paddle, Gumroad. They are a merchant of records that look like this:
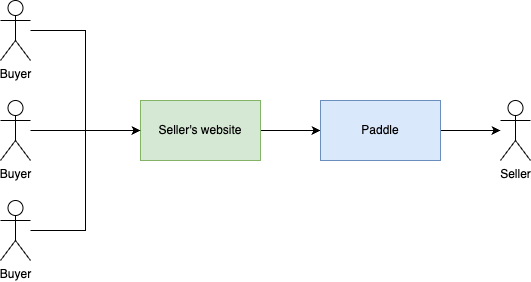
This is what's happening:
- A seller (or content creator) uploads a product to Paddle
- They integrate Paddle into their landing page
- Buyers buy the product from the landing page using a Paddle checkout form
- Paddle pays the seller every month
I personally use Paddle to sell my books and SaaS and it's a great service. The main benefit is that you don't have to deal with hundreds or thousands of invoices and VAT ramifications. Paddle handles it for you. They send an invoice to the buyer and apply the right amount of VAT based on the buyer's location. They also handle VAT ramifications. You, as the seller, don't have to deal with any of that stuff. They just send you the money once every month and you have only one invoice. It also provides nice dashboards and reports.
Every month they send payouts to their users based on the transactions. They also send a CSV that contains all the transactions in the given month.
This is the problem we're going to imitate in this chapter. Exporting tens of thousands of transactions in an efficient way.
This is what the transactions table looks like:
| id | product_id | quantity | revenue | balance_earnings | payout_id | stripe_id | user_id | created_at |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 3900 | 3120 | NULL | acac83e2 | 1 | 2024-04-22 13:59:07 |
| 2 | 2 | 1 | 3900 | 3120 | NULL | ... | 1 | 2024-04-17 17:43:12 |
These are two transactions for user #1. I shortened some UUIDs so the table fits the page better. Most columns are pretty easy to understand. Money values are stored in cent values so 3900 means $39. There are other rows as well, but they are not that important.
When it is payout time, a job queries all transactions in a given month for a user, creates a Payout object, and then sets the payout_id in this table. This way we know that the given transaction has been paid out. The same job exports the transactions for the user and sends them via e-mail.
laravel-excel is one of the most popular frameworks when it comes to imports/exports so we're going to use it in the first example.
This is what a typical export looks like:
namespace App\Exports;
class TransactionsSlowExport implements FromCollection, WithMapping, WithHeadings
{
use Exportable;
public function __construct(
private User $user,
private DateInterval $interval,
) {}
public function collection()
{
return Transaction::query()
->where('user_id', $this->user->id)
->whereBetween('created_at', [
$this->interval->startDate,
$this->interval->endDate,
])
->get();
}
public function map($row): array
{
return [
$row->uuid,
Arr::get($row->product_data, 'title'),
$row->quantity,
MoneyForHuman::from($row->revenue)->value,
MoneyForHuman::from($row->fee_amount)->value,
MoneyForHuman::from($row->tax_amount)->value,
MoneyForHuman::from($row->balance_earnings)->value,
$row->customer_email,
$row->created_at,
];
}
public function headings(): array
{
return [
'#',
'Product',
'Quantity',
'Total',
'Fee',
'Tax',
'Balance earnings',
'Customer e-mail',
'Date',
];
}
}
I've seen dozens of exports like this one over the years. It creates a CSV from a collection. In the collection method, you can define your collection which is 99% of the time the result of a query. In this case, the collection contains Transaction models. Nice and simple.
However, an export such as this one, has two potential problems:
- The
collectionmethod runs a single query and loads each and every transaction into memory. The moment you exceed x number of models your process will die because of memory limitations. x of course varies highly. - If your collection is not that big and the export made it through the query, the
mapfunction will run for each and every transaction. If you execute only one query here, it'll runntimes wherenis the number of rows in your CSV. This is the breeding ground for N+1 problems.
Be aware of these things because it's pretty easy to kill your server with a poor export.
The above job has failed with only 2,000 transactions:
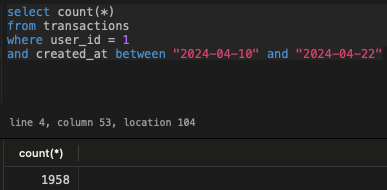
1,958 to be precise. The result is Allowed memory size exhausted:
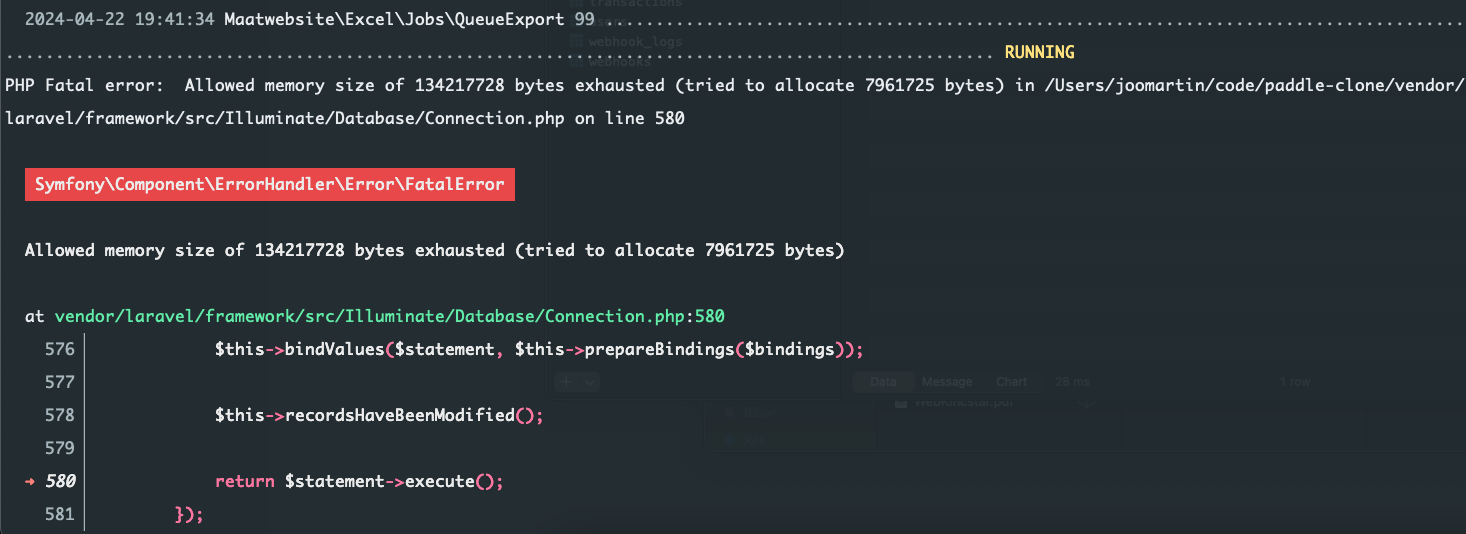
As you can see, it is executed in a worker. This is possible by two things:
-
The export uses the
Exportabletrait from the package, which has aqueuefunction -
The method that runs the export uses this
queuemethod:new TransactionsExport( $user, $interval, ) ->queue($report->relativePath()) ->chain([ new NotifyUserAboutExportJob($user, $report), ]);
This is how you can make an export or import queueable.
Fortunately, there's a much better export type than FromCollection, it is called FromQuery. This export does not define a Collection but a DB query instead that will be executed in chunks by laravel-excel.
This is how we can rewrite the export class:
namespace App\Exports;
class TransactionsExport implements FromQuery, WithHeadings, WithCustomChunkSize, WithMapping
{
use Exportable;
public function __construct(
private User $user,
private DateInterval $interval,
) {}
public function query()
{
return Transaction::query()
->select([
'uuid',
'product_data',
'quantity',
'revenue',
'fee_amount',
'tax_amount',
'balance_earnings',
'customer_email',
'created_at',
])
->where('user_id', $this->user->id)
->whereBetween('created_at', [
$this->interval->startDate->date,
$this->interval->endDate->date,
])
->orderBy('created_at');
}
public function chunkSize(): int
{
return 250;
}
public function headings(): array
{
// Same as before
}
public function map($row): array
{
// Same as before
}
}
Instead of returning a Collection the query method returns a query builder. In addition, you can also use the chunkSize method. It works hand in hand with Exportable and FromQuery:
- Queued exports (using the
Exportabletrait and thequeuemethod) are processed in chunks - If the export implements
FromQuerythe number of jobs is calculated byquery()->count() / chunkSize()
So in the chunkSize we can control how many jobs we want. For example, if we have 5,000 transactions for a given user and chunkSize() returns 250 which means that 20 jobs will be dispatched each processing 250 transactions. Unfortunately, I cannot give you exact numbers. It all depends on your specific use case. However, it's a nice way to fine-tune your export.
Using the techniques above, exporting 10k transactions is a walk in the park:
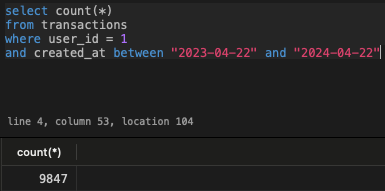
9,847 to be precise but the jobs are running smoothly. There are 40 jobs each processing 250 transactions:

The last jobs larave-excel runs are CloseSheet and StoreQueuedExport.
Imports
This is what a basic laravel-excel import looks like this:
namespace App\Imports;
class UsersImport implements ToModel
{
public function model(array $row)
{
return new User([
'name' => $row[0],
]);
}
}
It reads the CSV and calls the model method for each row then it calls save on the model you returned. It means that it executes one query for each row. If you're importing thousands or tens of thousands of users you'll spam your database and there's a good chance it will be unavailable.
Fortunately, there are two tricks we can apply:
- Batch inserts
- Chunk reading
Batch inserts
Batch insert means that laravel-excel won't execute one query per row, but instead, it batches the rows together:
namespace App\Imports;
class UsersImport implements ToModel, WithChunkReading
{
public function model(array $row)
{
return new User([
'name' => $row[0],
]);
}
public function batchSize(): int
{
return 500;
}
}
This will execute x/500 inserts where x is the number of users.
Chunk reading
Chunk reading means that instead of reading the entire CSV into memory at once laravel-excel chunks it into smaller pieces:
namespace App\Imports;
class UsersImport implements ToModel, WithChunkReading
{
public function model(array $row)
{
return new User([
'name' => $row[0],
]);
}
public function chunkSize(): int
{
return 1000;
}
}
This import will load 1,000 users into memory at once.
Of course, these two features can be used together to achieve the best performance:
namespace App\Imports;
class UsersImport implements ToModel, WithBatchInserts, WithChunkReading
{
public function model(array $row)
{
return new User([
'name' => $row[0],
]);
}
public function batchSize(): int
{
return 500;
}
public function chunkSize(): int
{
return 1000;
}
}
Generators & LazyCollections
What if you can't or don't want to use laravel-excel to import a large CSV? We can easily read a CSV in PHP:
public function readCsv(string $path): Collection
{
$stream = fopen($path, 'r');
if ($stream === false) {
throw new Exception('Unable to open csv file at ' . $path);
}
$rows = [];
$rowIdx = -1;
$columns = [];
while (($data = fgetcsv($stream)) !== false) {
$rowIdx++;
if ($rowIdx === 0) {
$columns = $data;
continue;
}
$row = [];
foreach ($data as $idx => $value) {
$row[$columns[$idx]] = $value;
}
$rows[] = $row;
}
fclose($stream);
return collect($rows);
}
fgetcsv by default reads the file line by line so it won't load too much data into memory, which is good.
This function assumes that the first line of the CSV contains the headers. This block saves them into the $columns variable:
if ($rowIdx === 0) {
$columns = $data;
continue;
}
$column is an array such as this:
[
0 => 'username',
1 => 'email',
2 => 'name',
]
fgets returns an indexed array such as this:
[
0 => 'johndoe',
1 => '[email protected]',
2 => 'John Doe',
]
The following block transforn this array into an associative one:
$row = [];
foreach ($data as $idx => $value) {
$row[$columns[$idx]] = $value;
}
$rows[] = $row;
At the end, the function closes the file, and returns a collection such as this:
[
[
'username' => 'johndoe',
'email' => '[email protected]',
'name' => 'John Doe',
],
[
'username' => 'janedoe',
'email' => '[email protected]',
'name' => 'Jane Doe',
],
]
It's quite simple, but it has one problem: it holds every row in memory. Just like with laravel-excel it will exceed the memory limit after a certain size. There are two ways to avoid this problem:
- PHP generators
- Laravel's LazyCollection
Since LazyCollections are built on top generators, let's first understand them.
PHP generators
With a little bit of simplification, a generator function is a function that has multiple return statements. But instead of return we can use the yield keyword. Here's an example:
public function getProducts(): Generator
{
foreach (range(1, 10_000) as $i) {
yield [
'id' => $i,
'name' => "Product #{$i}",
'price' => rand(9, 99),
];
}
}
foreach (getProducts() as $product) {
echo $product['id'];
}
Any function that uses the yield keyword will return a Generator object which implements the Iterable interface so we can use it in a foreach.
Each time you call the getProducts function you get exactly one product back. So it won't load 10,000 products into memory at once, but only one.
The function above behaves the same as this one:
public function getProducts(): array
{
$products = [];
foreach (range(1, 10000) as $i) {
$products[] = [
'id' => $i,
'name' => "Product #{$i}",
'price' => rand(9, 99),
];
}
return $products;
}
But this function will load 10,000 products into memory each time you call it.
Here's the memory usage of the standard (non-generator) function:
| # of items | Peak memory usage |
|---|---|
| 10,000 | 5.45MB |
| 100,000 | 49MB |
| 300,000 | PHP Fatal error: Allowed memory size of 134217728 bytes exhausted |
It reached the 128MB memory limit with 300,000 items. And these items are lightweight arrays with only scalar attributes! Imagine Eloquent models with 4-5 different relationships, attribute accessors, etc.
Now let's see the memory usage of the generator-based function:
| # of items | Peak memory usage |
|---|---|
| 10,000 | 908KB |
| 100,000 | 4.5MB |
| 1,000,000 | 33MB |
| 2,000,000 | 65MB |
| 3,000,000 | PHP Fatal error: Allowed memory size of 134217728 bytes exhausted |
It can handle 2,000,000 items using only 65MB of RAM. It's 20 times more than what the standard function could handle. However, the memory usage is only 32% higher (65M vs 49M).
Imports with generators
Now let's add a generator to the readCsv function:
while (($data = fgetcsv($stream, 1000, ',')) != false) {
$rowIdx++;
if ($rowIdx === 0) {
$columns = $data;
continue;
}
$row = [];
foreach ($data as $idx => $value) {
$row[$columns[$idx]] = $value;
}
yield $row;
}
The whole function is identical except that it's not accumulating the data in a $rows variable but instead, it yields every line when it reads it.
In another function we can use it as it was a standard function:
$transactions = $this->readCsv();
foreach ($transactions as $transaction) {
// ...
}
This is the equivalent of chunk reading in laravel-excel. Now let's implement batch inserts as well.
This would be the traditional one-insert-per-line solution:
$transactions = $this->readCsv();
foreach ($transactions as $transaction) {
Transaction::create($transaction);
}
It runs one DB query for each CSV line. It can be dangerous if the CSV contains 75,000 lines, for example.
So instead, we can batch these into bigger chunks:
$transactions = $this->readCsv();
$transactionBatch = [];
foreach ($transactions as $i => $transaction) {
$transactionBatch[] = $transaction;
if ($i > 0 && $i % 500 === 0) {
Transaction::insert($transactionBatch);
$transactionBatch = [];
}
}
if (!empty($transactionBatch)) {
Transaction::insert($transactionBatch);
}
It accumulates transactions until it hits an index that can be divided by 500 then it inserts 500 transactions at once. It there were 1,741 transactions for example, the insert after the loop inserts the remaining 241.
With generators and a little trick, we achieved the same two things as with laravel-excel:
- Loading only one line into memory at once
- Chunking the database writes
Imports with LazyCollections
LazyCollection is a combination of collections and generators. We use it like this:
$collection = LazyCollection::make(function () {
$handle = fopen('log.txt', 'r');
while (($line = fgets($handle)) !== false) {
yield $line;
}
});
It works the same way as Generators but the make function returns a LazyCollection instance that has lots of useful Collection methods such as map or each.
Our example can be rewritten as this:
public function readCsv(): LazyCollection
{
return LazyCollection::make(function() {
$stream = fopen(storage_path('app/transactions.csv'), 'r');
if ($stream === false) {
throw new Exception('Unable to open csv file at ' . storage_path('app/transactions.csv'));
}
$rowIdx = -1;
$columns = [];
while (($data = fgetcsv($stream, 1000, ',')) != false) {
$rowIdx++;
if ($rowIdx === 0) {
$columns = $data;
continue;
}
$row = [];
foreach ($data as $idx => $value) {
$row[$columns[$idx]] = $value;
}
yield $row;
}
});
}
The function that uses the readCsv method now looks like this:
$this->readCsv()
->chunk(500)
->each(function(LazyCollection $transactions) {
Transaction::insert($transactions->toArray());
});
We can leverage the built-in chunk method that chunks the result by 500.
Once again, we achieved two things:
- Loading only one line into memory at once
- Chunking the database writes
This whole article comes from my new book Performance with Laravel.
Check it out:
